
《Automatic Generation of Text Descriptive Comments for Code Blocks》阅读笔记
Published:
原文链接:https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16492/16072
作者:Yuding Liang, Kenny Q. Zhu
简介:本文提出了一个新的框架来自动生成源代码块的描述性注释。提出了一个新的递归神经网络-Code-RNN。通过Code-RNN从源码中提取特征并嵌入向量中。当此向量输入到新的递归神经网络Code-GRU时,生成准确率较高的代码注释。
该读书笔记由谢佳展同学提供
研究概况
现有工作
已有的工具有MOSES、Seq2Seq、基本RNN、CODE-NN。将本文提出的Code-RNN与前人的实验相比,生成的代码注释准确率更高。
具体细节
模型结构
Code-RNN是一种新的递归神经网络,用于封装源码的结构信息。与其他递归神经网络的二叉树形式相比,Code-RNN是任意树形式。
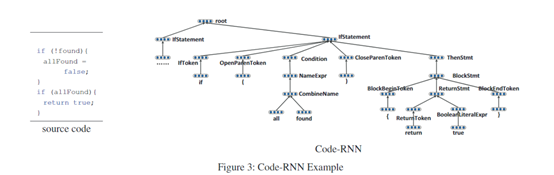
解析树中的每个节点都由向量表示。
Code-RNN的两种模型如下:
- Sum 模型
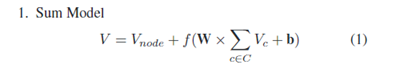
- Aveage 模型
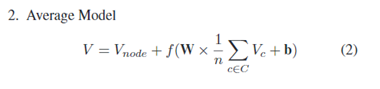
V是以N为根的子树的向量表示,Vnode是表示N本身句法类型的向量。
Vc是V的子树向量。在训练过程中参数w和b被调整。
通过这个模型递归地自下而上执行,已获得根节点的向量表示,即整个代码块的向量表示。
语义提取
一是从单词连接形式分割为多个单词,如allFound可被分割成all 和found 二是从单词缩写中恢复完整的单词。
现有的RNN中,不能将代码块表示的向量直接输入到RNN单元中。因此,本文提出了基于GRU的RNN变体。
整体流程
生成注释的过程如下:
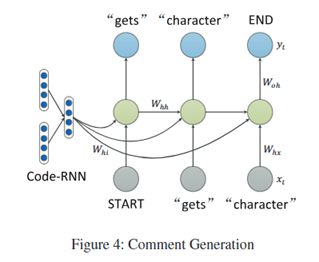
在上图的例子中,首先将START token作为模型的初始输入,并将代码块的向量输入到隐藏层中。结束计算后,进行反向传播。第二步是将gets作为初始输入,再将代码块向量输入到隐藏层中,并获得ht-1。重复进行上述步骤。涉及参数公式如下:
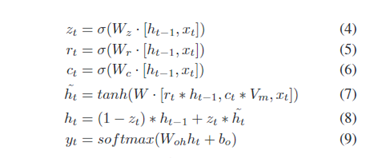
在测试中,输入START TOKEN并选择可能性最大的单词作为输出,然后从第二步开始,每一步的输入字就是前一步的输出字,直到输出为END TOKEN为止。
评估
- 第一部分评估code-RNN模型对不同的源码进行分类的能力。数据集为Google Code Jam竞赛(2008-2016)。
与Language Embedding和basic RNN进行比对。
LE将源码视为单词序列进行训练,故只关注单词的语义而不关注代码结构。
Basic RNN在进行代码块的树结构计算时用占位符一致替换标识符来解析树,故只关注代码结构而不关注单词语义。
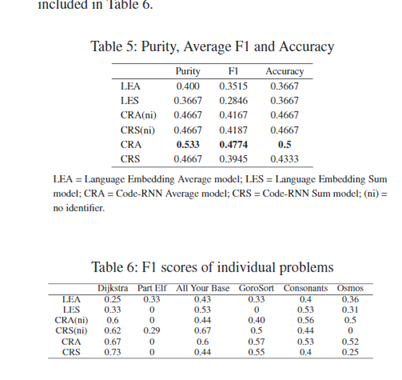
Code-RNN效果更好。 - 第二部分评估本模型的有效性,即生成注释的准确性。
数据集:
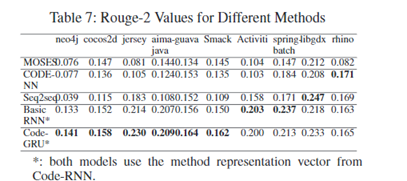
10个java开源项目
与MOSES、Seq2seq、BasicRNN、Code-NN对比。

可以看出code-RNN的效果更好。