《DeepLearning Similarities from Different Representations of SourceCode》阅读笔记
Published:
原文链接: http://www.cs.wm.edu/~mtufano/publications/C9.pdf
作者:Michele Tufano,Cody Watson,Gabriele Bavota,Massimiliano Di Penta,Martin White,Denys Poshyvanyk
文章来源: MSR 2018
简介: 本文针对代码克隆检测,提出了基于Deep Learning自动学习代码相似性的方法,在混合四个representation的代码克隆检测中取得了较好的结果。
研究概况
研究背景
源代码分析是许多软件工程任务的坚实基础。源代码分析方法依赖于许多不同的代码表示,例如源代码中的标识符、注释、抽象语法树、控制流图、数据流、字节码等,代码表示提供了不同的抽象级别,这些抽象级别在源代码之间创建了显式和隐式的关系。
现有的克隆检测方法利用基于手动指定特征集合的算法,例如:基于文本的、基于字符串的、基于token的、基于AST的、基于图形的和基于词典的等等。
前人工作和不足
事实上已经有很多人使用DL来替代手动特征工程进行软件工程相关的研究(不局限于代码克隆检测),例如:
- 通过递归循环编码器进行
representation的学习以实现代码克隆检测: 将源代码用标识符流和语法类型进行表示,提取出representation。 - 基于
DL和IR(Information Retrieval)的错误定位:利用IR技术自动提取文本相似性特征,之后神经网络通过学习将bug和token进行关联。 - 基于
Deep Belief Network(深度信任网络)的缺陷检测:使用DBN从AST中提取token vector,用来学习语义特征进而进行缺陷检测。
对于以上的工作来说,他们可以说是特征的选择都是根据软件工程研究人员或者这个领域的专家的直观的感觉或者经验来选取的,而且这些方法都需要大量的数据集的支持。
我们的工作
在本文中,我们提出了一个基本问题,底层的代码表示是否能成功应用于自动学习代码相似性。然后在我们的方法中,我们使用了identifier,AST,CFG,bytecode四个representation来表示代码,进而通过DL来检测代码的相似性。而且,我们还研究了模型的组合是否优于单个模型的性能,实验结果符合我们的预期,组合模型提供了更加全面的代码表示,性能要更好。
具体细节
过程简介
我们的方法可以概括如下。 首先,以我们希望分析的不同粒度(例如,类,方法)选择代码片段。 接下来,对于每个选定的片段,我们提取其四种不同的表示(即标识符,AST,字节码和CFG)。 代码片段被嵌入为连续值矢量(continuous valued vectors)。为了检测相似的代码片段,在嵌入(embeddings)之间计算距离。
提取representation
给定一个项目,统计所有的.java和.class文件,对于java文件利用Eclipse中的JDT工具构造语法树,采用visitor模式来遍历所有的节点,选择所有的类或者方法,同时我们丢弃了接口和抽象类,分析他们没有什么意义,同时过滤掉小于10个语句的代码。
- identifiers: 通过遍历语法树的叶子节点的值来提取特征,同时将常量分别用
<int>,<float>,<char>,<string>等值进行代替。 - AST: 通过遍历语法树中的中间节点来提取所有的语句类型,这里我们删除了SimpleName 和 QualifiedName两个节点,第一,前面的representation已经包含了这个特征,第二提取的语句中这两条语句过多,影响最终的实验效果。
- CFG: 通过soot工具提取class文件中类或者方法的控制流特征。
- bytecode,通过java自带的反编译工具javap来提取class文件中的字节码特征,同时,我们只保留指令的名称,对于指令后面的数字所代表的的含义进行了忽略。
Deep Learning 进行学习
采用两种策略来学习嵌入(embedding)表示,对于标识符、AST、bytecode我们采用基于DL的方法,对于CFG我们采用Graph embedding技术。
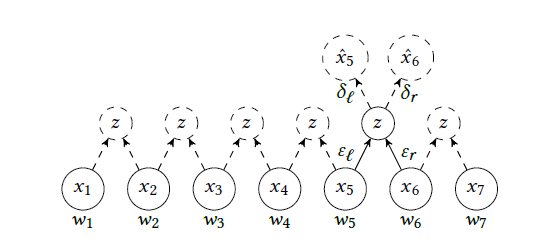
- DL 策略: 分为两步,第一步用
RtNN进行Word Embedding的学习,第二步是用Recursive Autoencoder(http://ai.stanford.edu/~ang/papers/emnlp11-RecursiveAutoencodersSentimentDistributions.pdf)进行句子embedding的学习:
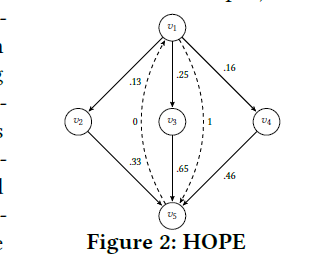
- Graph Embedding 策略: 为了生成用于CFG表示的嵌入,我们使用图嵌入技术HOPE(High-Order Proximity preserved Embedding)。 HOPE学习两个嵌入向量;源矢量和每个顶点的目标矢量。然后根据边的权重和它们的性质(源或目标)为这些矢量分配值。 例如,考虑图2中的图。每个实线边是有向边,虚线边捕捉图的非对称传递性。为v1创建的矢量作为目标矢量将为0,因为没有路径将v1指定为其目标。但是,分配给v5目标矢量的值会更高,因为许多路径以v5作为其目标结束。HOPE通过每个顶点的奇异值分解创建和学习图的嵌入。 然后,通过对节点嵌入进行均值汇聚,可以生成整个图的单个嵌入。
https://github.com/palash1992/GEM
探索相似性
通过统计每个representation生成出来的距离矩阵,并根据相应的阈值来探索代码克隆
组合模型
利用集合学习技术来将每个单独的representation学习出来的距离进行组合。最常用的集合学习技术就是求一些代数表达式(总和、平均值、乘积、中值等),例如加权平均和:
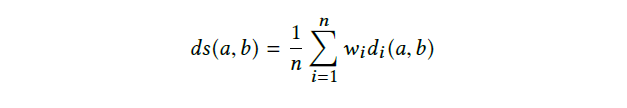
另一种方法就是采用投票的方法。
也可以采用随机森林的方法对结果进行统计。
实验设计
该实验的目的是调查是否可以从不同类型的程序表示中学习源代码相似性,目的是了解是否可以组合不同的表示形式以获得更好的结果,或者在某些表示形式不可用时使用替代表示形式。 更具体地说,该研究旨在回答以下研究问题(RQ):
- 在检测相似的代码片段时,不同的表示法(
representation)是否有效 - 不同的
representation之间是否存在互补 - 组合模型是否有效
- DL模型适用于检测不同项目中的克隆吗?
- 训练有素的基于DL的模型可以重用于以前不可见的不同项目吗?
数据集选择
两个数据集,第一个是十个开源的java项目(from the Qualitas.class Corpus),第二个是46个开源的java Libraries(from the Apache commons libraries).
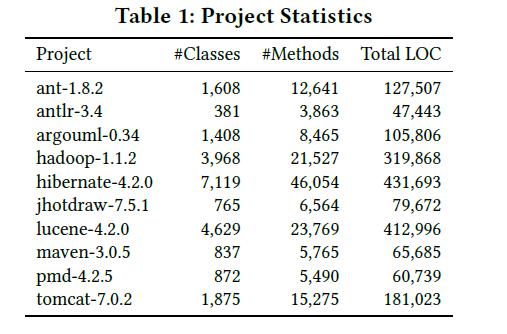
实验过程和数据分析
RQ1:How effective are different representations in detecting similar code fragments?
将每个提取的representation的特征进行embedding,其中Identifiers,AST,bytecode的embedding size为300,CFG的embedding size为4.
得到距离矩阵之后,我们对类级和方法级的克隆进行判断,阈值为:
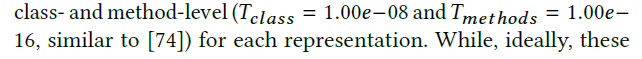
我们将每个representation得到的克隆对取并集,并对每个克隆对进行分析,分析他们的representation判断的是否正确,一个克隆对对应着四个判断依据,例如TFFF说明只有identifier第一个特征跑出来的结果说明该克隆是一个克隆对。 所以一共有15种可能的情况(FFFF不会出现),对于每种情况,随机抽取95%置信水平和±15%置信区间的统计显着样本。接下来选择三个评估人员独立的评估样本的克隆级别,决定样本是true or false positives.获取三个评估者手动标注的数据集后,我们计算两个判断者的一致意见获得最终的数据集(例如,三个人里面有两个人认为是postive的我们就认为是positive).针对最终的数据集,我们计算了每种情况的(TTTT,TFFF等)的精确度和召回率。(true positive,false positive)。
RQ2:What is the complementarity of different representations?
根据RQ1中的数据,我们计算获得的数据集中的交集和差异集.
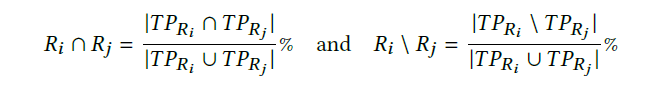
(TRi 代表的是true positive identified by representation i)
接下来计算由单一表示唯一标识的克隆对的百分比,并且由representation忽略:
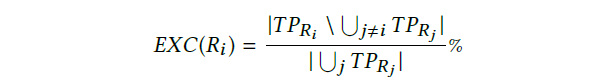
我们还计算每对表示之间的Spearman秩相关,以调查从相同对伪像上的不同表示计算出的距离相关的程度。
RQ3:How effective are combined multi-representation models?
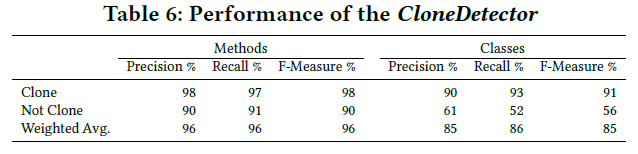
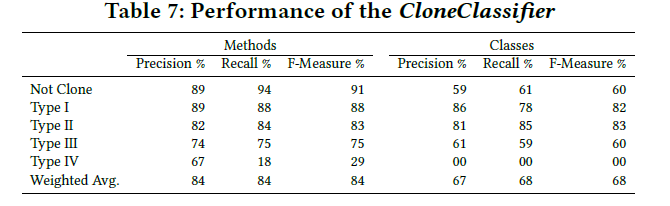
为了回答这个问题,我们提出了两个组合模型第一个是CloneDetector,判断true positive or false positive,另一个是CloneClassifier,判断clone type(四个类型) 所使用的数据也就是RQ1中手动标记的数据。为了训练这两个模型,我们依靠随机森林采用常用的10倍交叉验证技术来划分训练和测试集。
RQ4: Are DL-based models applicable for detecting clones among different projects?
对46个开源的java libraries进行试验。
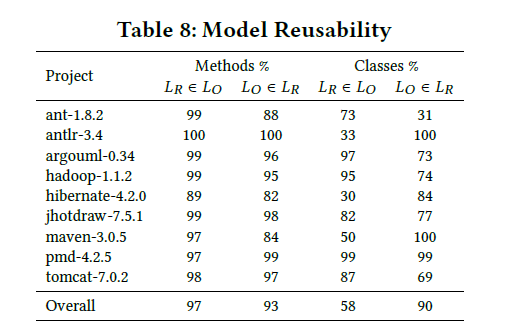
RQ5: Can trained DL-based models be reused on different, previously unseen projects?
DL模型的一个缺点是训练时间长。如果这些模型可以在属于不同领域的不同项目中重复使用,则此培训时间可以摊销。阻碍这些模型重用的主要因素是出现新的词汇,导致我们在预测的时候出现差异。 为了解决这个问题,我们决定只针对AST representation做实验进行观察,因为AST中的词汇是固定,只要是java项目用jdt提取的值,不会出现新的词汇,然后我们训练了一个java项目中的AST模型,然后用这个模型产生剩下9个模型的embedding,然后拿原来模型产生的embedding (Lo) 和重用模型产生的embedding (LR)进行对比。
实验结果
RQ1
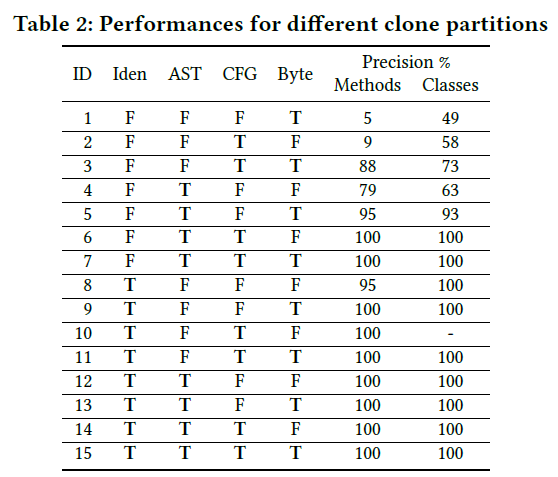
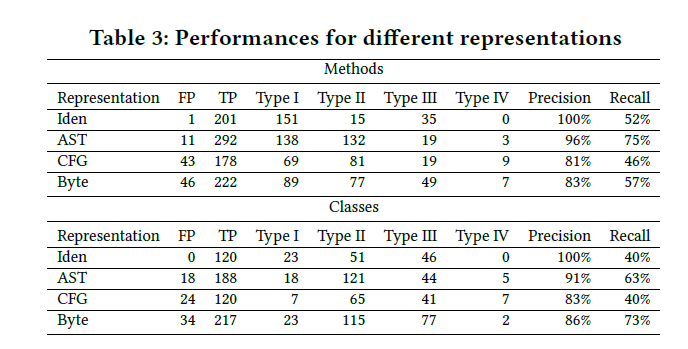
RQ2
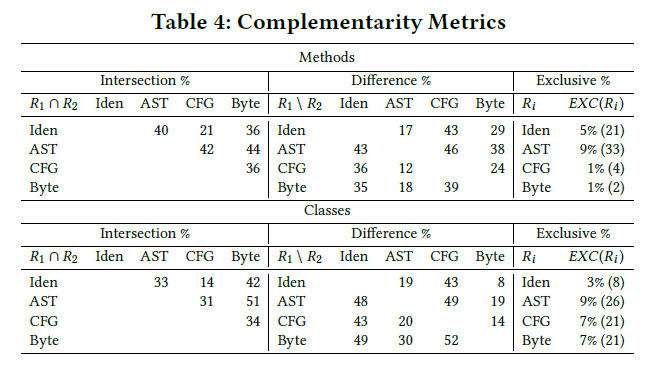
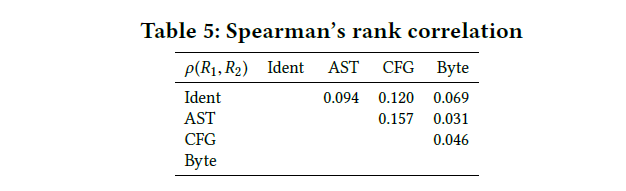
RQ3
RQ5