
高阶函数初探(五)
Published:
这周主要根据上次讨论的内容统计数据和作图,但是在统计数据的过程中发现了不少问题,因此对实验又重新进行了更新,提高数据的准确度。
统计数据
按照之前的讨论方向,除了之前的数据之外还需要增加以下几个内容:
- 高阶函数声明的每种类型的调用次数(>=2,1,0)
- private 类型的高阶函数的声明和调用情况,存不存在private 高阶函数调用次数为0,(Scala 语言默认函数为public)
- 统计Scala语言中高阶函数和lambda之间的关系,统计交并集
- 统计一个项目中是否存在20%的人写了80%的高阶函数代码
- 统计高阶函数调用每种类型的作者数量
发现的问题
在统计第一个数据时,即每种类型的调用次数时发现调用次数为0的声明太多了:
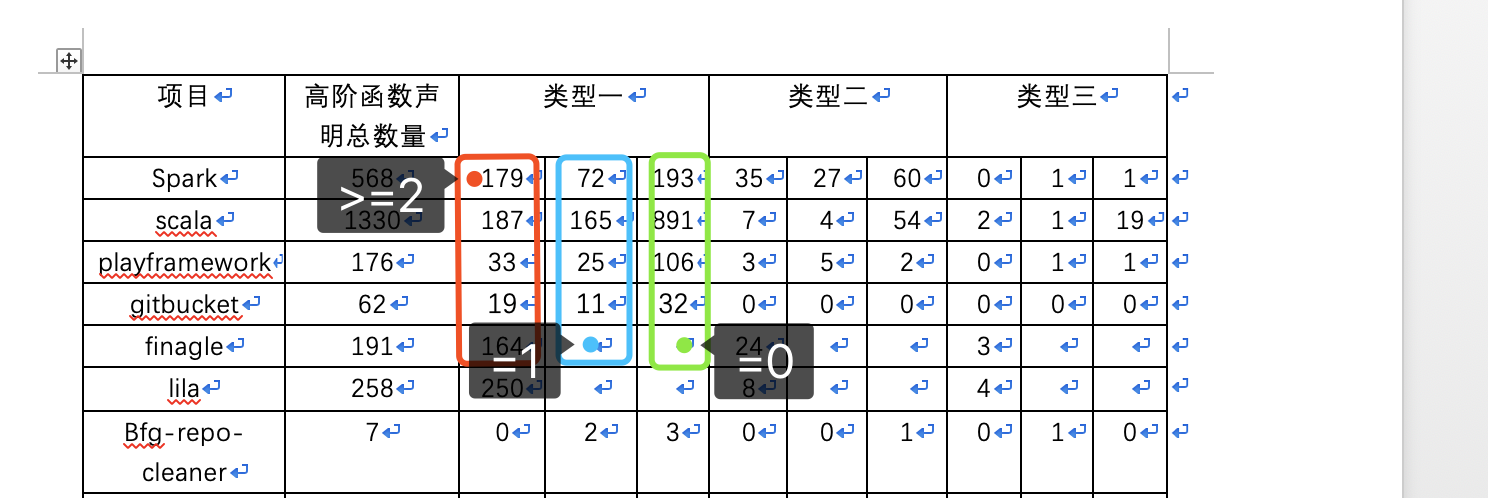
这个太不符合常理,一般除了接口外不会有人声明函数不调用,于是我就简单的查看一些没有被我程序检查出来的调用,发现:
- 有些程序没有被Scalameta识别出来是函数调用:
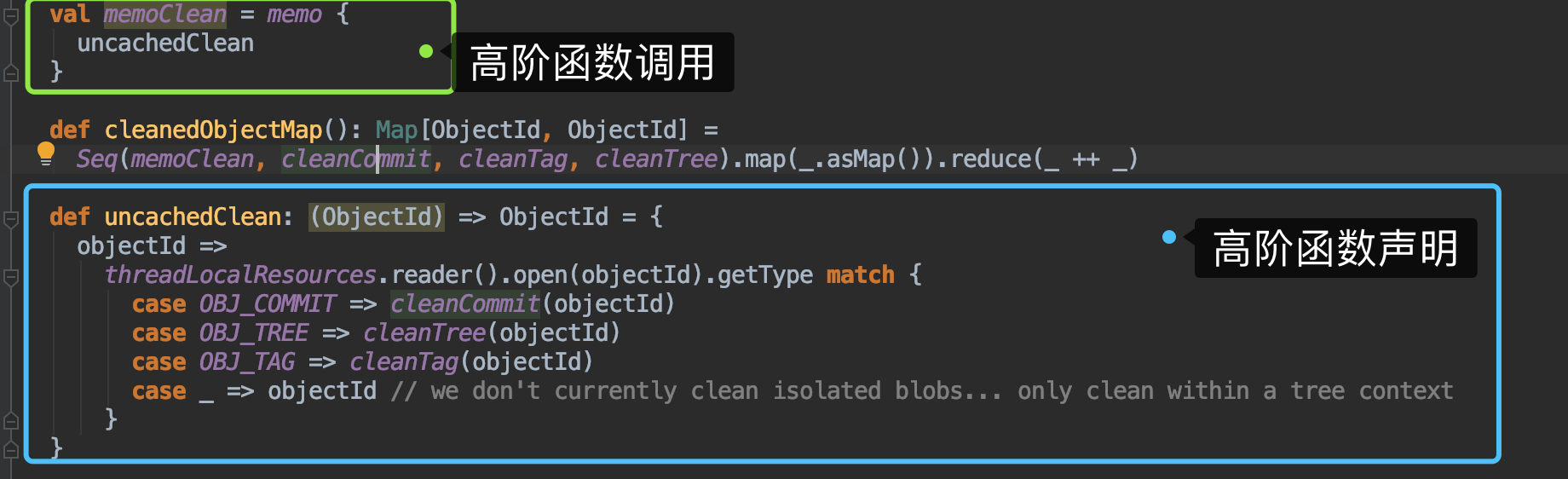
- 图片中的函数是一个返回一个函数的高阶函数,它在另一个val 定义中被调用,但是在scalameta看来就是一个字符串并不是函数调用。
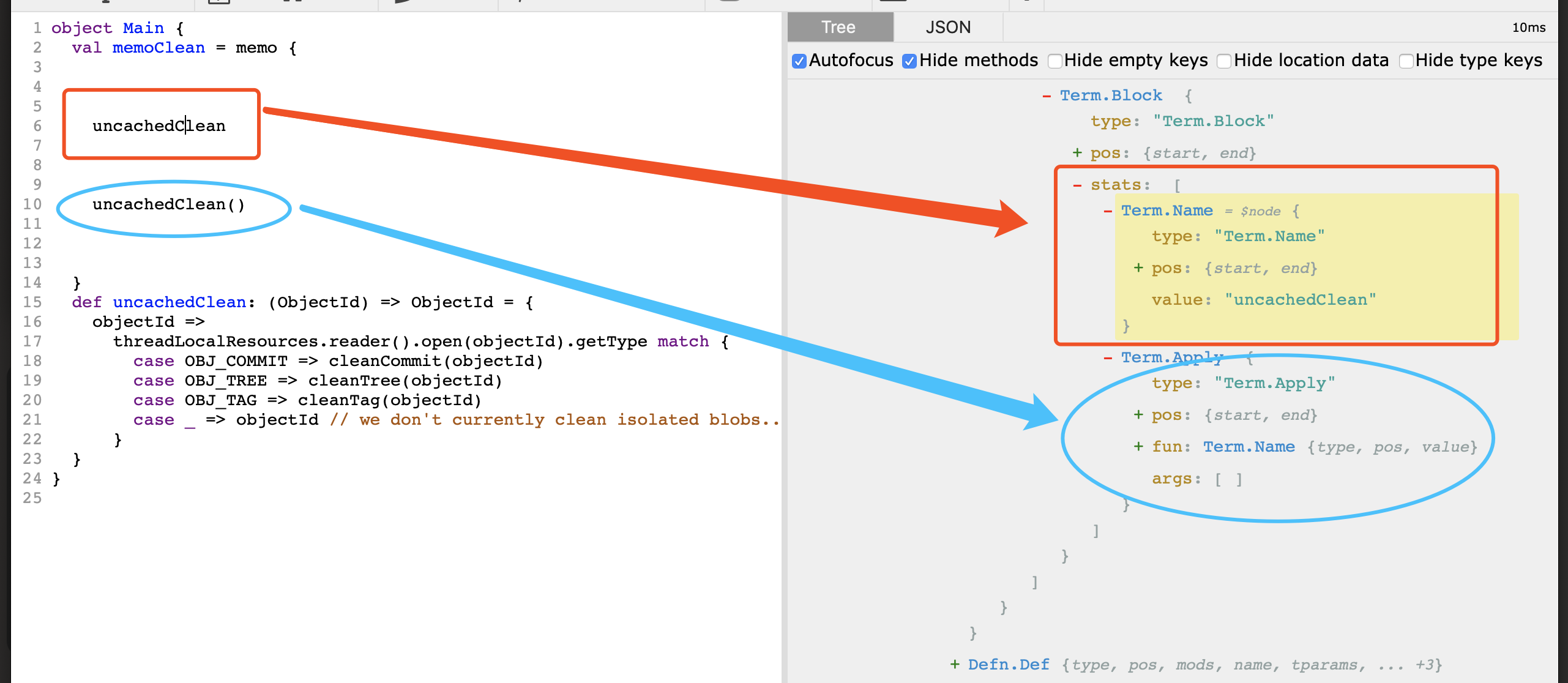
- 仅仅是加了一个括号就变成了调用(Term.Apply()).
- 有些程序调用了其他包里面的函数不容易分析:
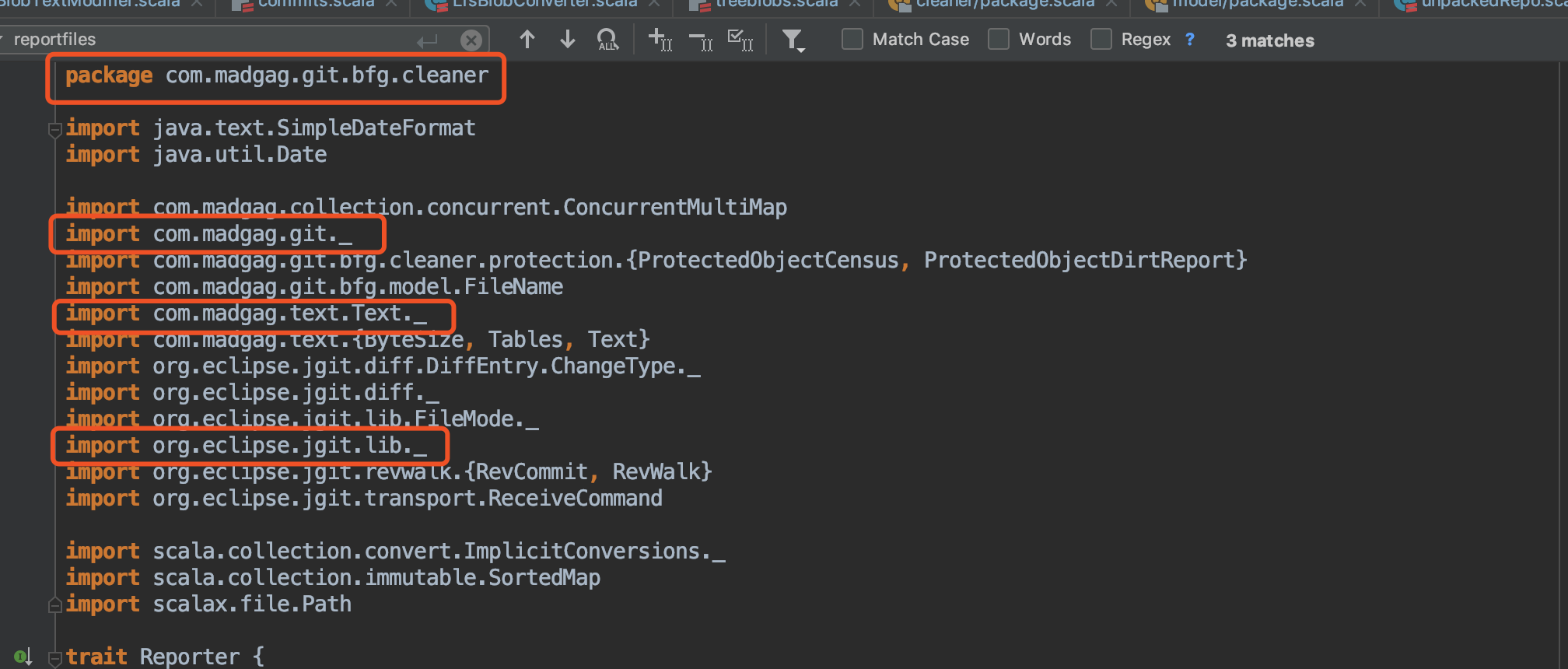
- 同一个包里面所有函数
-代表导入一个包里面的所有类,类似java里面的*, 有些函数调用在一个文件中只出现了一次而且前面也没有类修饰,只是像getFile(fileName)这样就不容易分析这个函数调用到底属于谁。
以上几个问题都是在在统计中发现的,其他的一些情况像嵌套函数暂时还没有列出来。
更新思路
介于上面的问题,我决定尝试使用语义数据库来尝试一下,之前跟玄老师介绍过,这个是Scalameta开源组织另一个工具,但是我在几个大项目中(spark,scala..,)中尝试了编译中断,无法通过编译。这周我将这个工具尝试用在其他的项目上,经过两三天的配置项目,最终得到了11个项目的语法数据库。
语法数据库
语法数据库的内容:
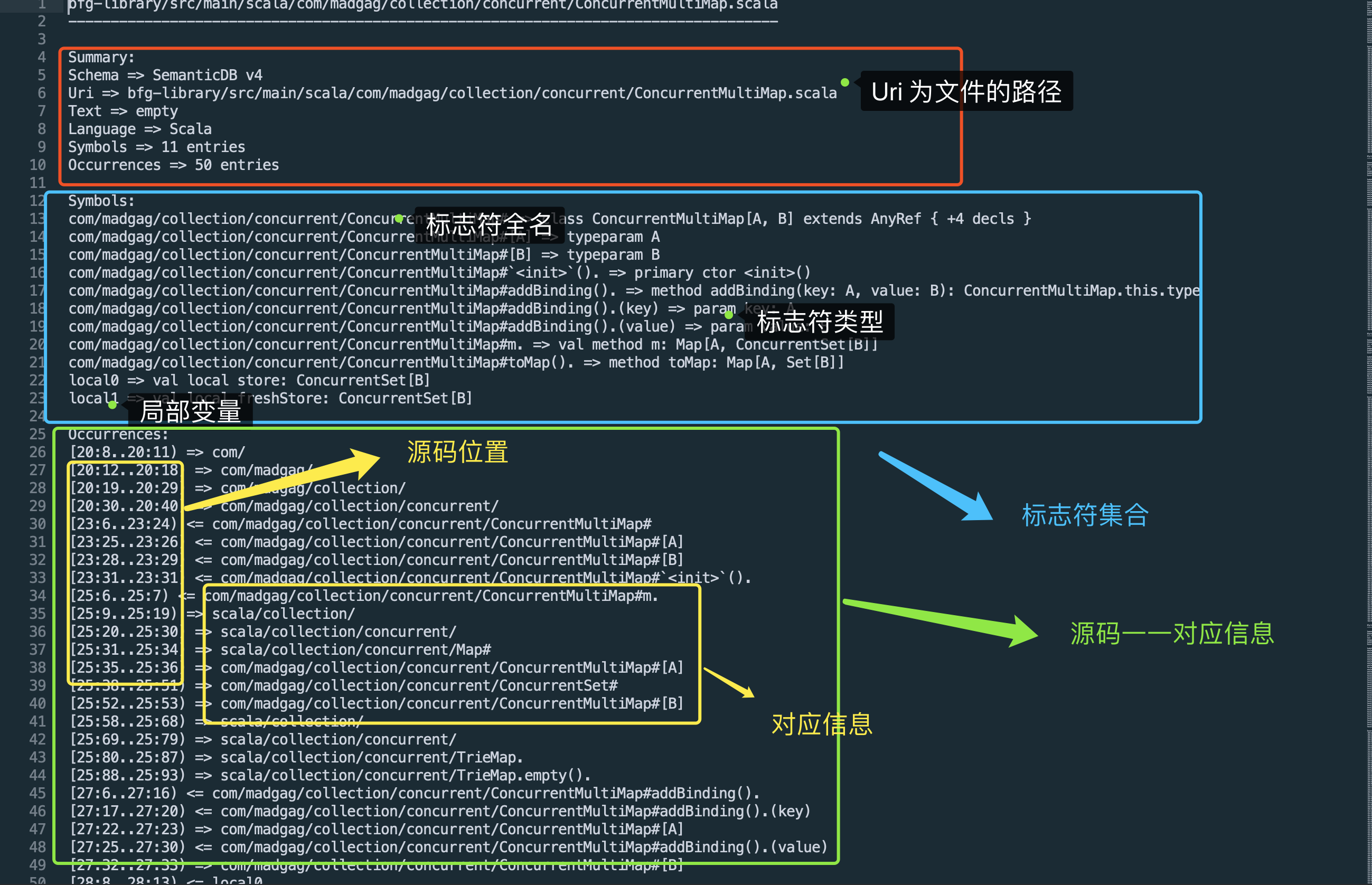
根据语法数据库的内容,我们可以在Symbol中找到函数的声明,在Occurrences中查找函数的调用。通过语法数据库我们可以得到:
- 所有函数声明(普通函数,高阶函数)
- 函数声明是否是private
- 函数声明中高阶函数的类型
- lambda函数声明(lambda是有函数声明的)
- 函数是否是局部函数(嵌套函数)
- 所有函数的调用(普通函数,高阶函数)
- 函数调用在源代码中的具体位置
但是语法数据库我们无法得到:
- 函数调用的类型
- 没有声明的lambda匿名函数的数量
针对后两个我们无法得到的东西我们可以通过其具体的位置,然后通过语法分析,字符串匹配来得出。
使用语法数据库的初步结果
- 11个得到语法数据库的项目:
- bfg
- fpinscala
- framework
- gatling
- gitbucket
- lila
- sbt
- scalaz
- scala-js
- scalding
- shapeless
- 高阶函数声明和调用对比
| 语法分析高阶函数声明 | 语法分析调用 | 语义分析声明 | 语义分析调用 | |
|---|---|---|---|---|
| bfg | 7 | 3 | 27 | 11 |
| fpinscala | 464 | 416 | 700 | 910 |
| framework | 176 | 151 | 468 | 328 |
| gitbucket | 62 | 256 | 138 | 624 |
| gatling | 101 | 110 | 315 | 379 |
| sbt | 512 | 622 | 710 | 1202 |
| shapeless | 97 | 36 | 502 | 102 |
| lila | 258 | 391 | 453 | 699 |
偶然发现的数据
在查找如何使用配置semanticdb的时候,偶然发现了scalameta作者收集到的一些数据(所用到的工具版本不一致),作者一共统计了91个项目的数据,其中有几个是我们20个项目中的,我认为可以作为后面实验的补充数据,至少可以确定能够配置成功。
GitHub 网址: https://github.com/olafurpg/scala-experiments
91个项目列表: https://docs.google.com/spreadsheets/d/1btkCiF30Wb9MJti6LDc9og788XqXBKgwEhIdKb9aloc/edit#gid=1799045603
之后的实验打算
- 增加更多的项目并再次尝试配置没有成功的项目。
- 将语法分析和语义分析的数据结合起来再加上作者。
- 按照基本数据统计之前讨论的所需要的数据。