简单代码克隆代码检测(六)(克隆工具第一版本)
Published:
本文主要介绍根据前几次的实验,编写、整合一个用于检测scala代码克隆的工具,目前只是第一版本。
实验简述
通过前几期的博客我已经知道了检测代码克隆的具体流程,基本上分以下几步,从源代码提取词->word embedding->sentence embedding->统计句子向量之间的距离->筛选出距离小于某个值的克隆对。之前参考的实验只提供了从word embedding到统计句子向量之间的距离的部分代码,而且使用的是matlab代码,所以我想把所有的流程整合到一起,尽量用同一种语言进行实现。
将提取特征的scala代码打成jar包
将之前写的提取scala的代码打成jar方便使用,具体的流程参考链接: https://blog.csdn.net/freecrystal_alex/article/details/78296851
之后在命令行试验了一下,居然出错了,在编译器里好好的,查看了一下错误

网上说是文件读取的问题,读取的文件里面有中文字符抛出异常,尝试了网上说的几个方法,最终是加了一行代码解决这个问题

最终jar执行无误:

jar包的输入参数有两个,一个是-leafor-path对应的是提取第一个还是第二个representation,第二个参数是项目的绝对路径,输出的是两个txt文件,一个是提取的特征,用于实验,另一个是每个特征对应scala文件的目录,方便查找对应的源代码。


修改word embedding代码
之前word embedding 是直接调用源码来实现,需要到linux系统中,先make,再调用,比较麻烦,我直接问赵俐俐学姐要了之前做实验的python的代码,基本上实现了word embedding这个部分的功能。
修改autoencode代码
之前的autoencode的代码是用matlab写的,我想把它转换成python语言,在github上搜了一下,有两个版本,一个是java版本,论文原作者写的: https://github.com/sancha/jrae
另一个是python版本的,是清华的一个博士生在2014年写的: https://github.com/pengli09/str2vec
为了方便与word embedding 整合,我选择了python版本的autoencoders 。
接下来就是漫长的~配置环境的过程,在代码的主页上给出了代码所需的库,
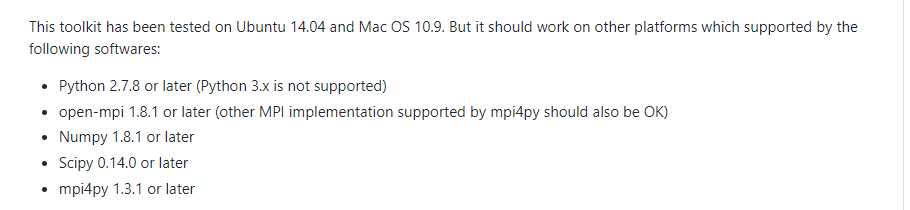
其他的都能够在服务器上简单进行配置(linux),但是就是openmpi这个包,一直出错,整了好久,都没有成功,而且我用的还是腾讯云的服务器,很卡很慢,所以就决定直接在本地的windows系统进行试验,参照博客将整个环境配置好了: https://blog.csdn.net/mengmengz07/article/details/70174905
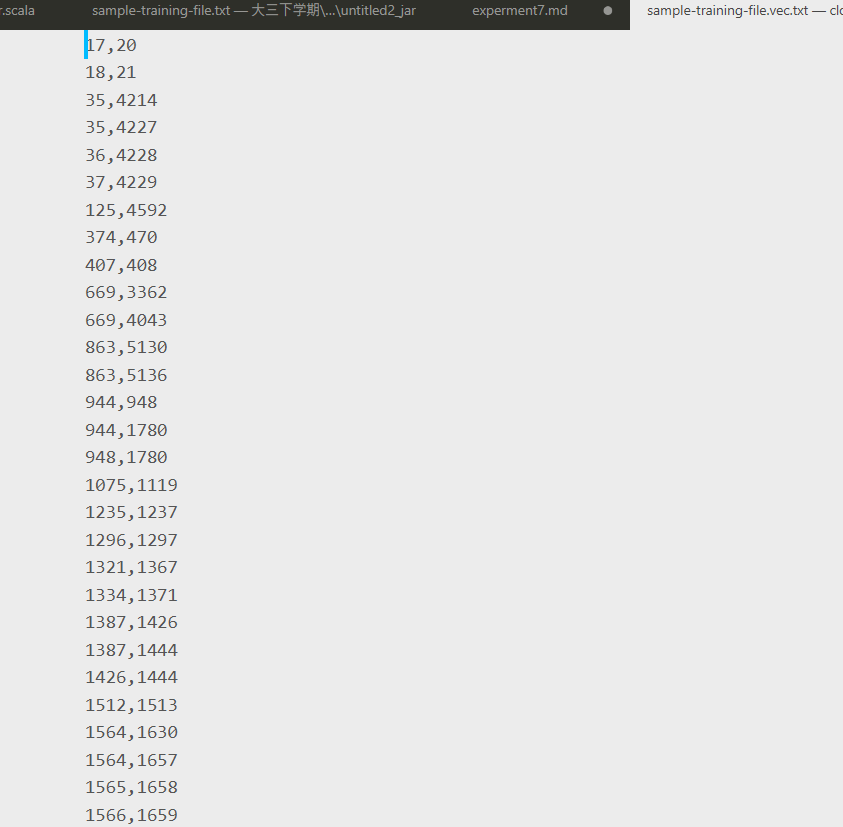
统计相似的克隆代码
上面说的python版本的autoencode最终输出的是一个句子的向量,没有给出具体的距离矩阵和相似代码的id,所以就修改了一下内部代码,利用python spicy 包里的函数生成了距离矩阵,并统计了距离小于1e-16的代码对。
程序的运行时间
像提取数据和word embedding的运行时间都比较短,可以不用担心,主要是这个autoencode运行时间很长,我在本地上跑,5000条样本,87条词向量,最大迭代为2次 运行的时间大概在35分钟左右,对比matlab来说短了一点点,并没有变的非常快,可能是我机子本身性能的问题。还有就是,论文中推荐迭代次数最好在100到200之间,我们现在2次迭代就那么长时间,感觉之后的时间会更长。这个问题有待解决。
工具使用说明:
项目结构截图:
运行 jar包 提取 representation
java -jar scala_parser.jar -path\-leaf {file_path}
将生成的 sample-training-file.txt 文件放到input文件夹下
执行 run_word2vec.sh
./run_word2vec.sh
这里没有参数进行输入,我把参数都写在.sh文件里面,之后修改可以在.sh文件中进行修改,一共三个参数,输入文件、输出文件、embedding size
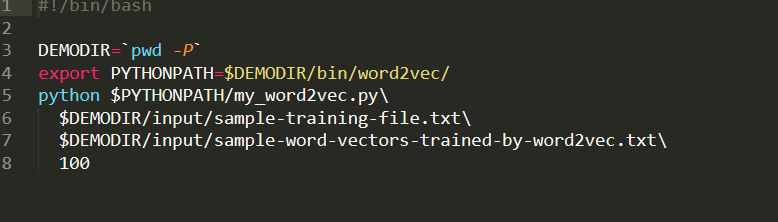
执行 mpi-train.sh
./mpi-train.sh {coreNum}
这里需要输入一个coreNum参数,意思是使用电脑里面核的个数
执行 compute-vector.sh
./compute-vector.sh
最终的结果文件
最终会在output文件夹中生成一个sample-training-file.vec.txt文件 ,里面是相似代码的id,跟之前我们第一步生成的sourceName.txt文件中的行数进行对比,查找源文件中的代码,(注意因为id是从0开始的,所以对应的行数为实际的行数减1)