简单代码克隆检测一(AST leaf)
Published:
今天主要将昨天得到的数据,放到之前看到的模型中跑了一下,看了一下效果,简单叙述一下实验。
- 实验思路:
- 将提取的Scala叶子节点的特征作为文本数据,输入到
AutoenCODE中 :AutoenCODE is a Deep Learning infrastructure that allows to encode source code fragments into vector representations, which can be used to learn similarities. https://github.com/micheletufano/AutoenCODE 基本上所有的代码这个网站已经提供了,所以只要将代码clone到本地,配置一下环境就可以开始我们的实验。具体的AutoenCODE的原理,我会在以后的博客中详细的解释,本篇博客主要讲如何使用这个框架。
- 将提取的Scala叶子节点的特征作为文本数据,输入到
- 实验步骤:
- 按照
AutoenCODE给的教程,第一步是将我们整理的数据转化成词向量,这里他使用的工具是word2vec,这里注意一下,他的这个word2vec需要build但是windows系统不支持这个build,所以我将转化词向量的这部分的工作转移到了centos服务器上进行,最终得到了测试样本的所有的词向量的数据。 - 接下来就将这个词向量输入到
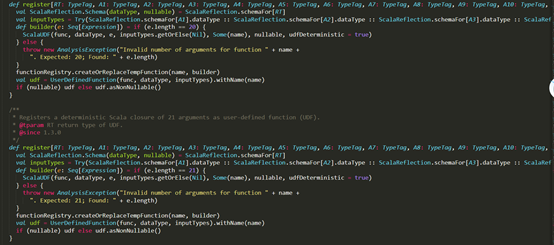
Recursive Autoencoder(论文中提及是一个斯坦福的情感分析器)中去,最终得到五个结果文件(这里提及一点,训练时间实在是太长了,源代码是使用matlab写的。27000条数据整整跑了一个小时,而且CUP满负荷运行,可能是我的电脑配置低,之后需要优化)。分别是:data.matcontains the input data including the corpus, vocabulary (a 1-by-V cell array), and We (the m-by- V word embedding matrix where m is the size of the word vectors). So columns of We correspond to word embeddings. corpus.dist.matrix.matcontains the distance matrix saved as matlab file. The values in the distance matrix are doubles that represent the Euclidean distance between two sentences. In particular, the cell (i,j) contains the Euclidean distance between the i-th sentence (i.e., i-th line in corpus.src) and the j-th sentence in the corpus.corpus.dist.matrix.csvcontains the distance matrix saved as .csv file.corpus.sentence_codes.matcontain the embeddings for each sentence in the corpus. The sentence_codes object contains the representations for sentences, and the pairwise Euclidean distance between these representations are used to measure similarity.detector.matcontains opttheta (the trained clone detector), hparams, and options.
这里对我们最有用的就是那个矩阵,它显示两句话的距离大小,越小越相似。
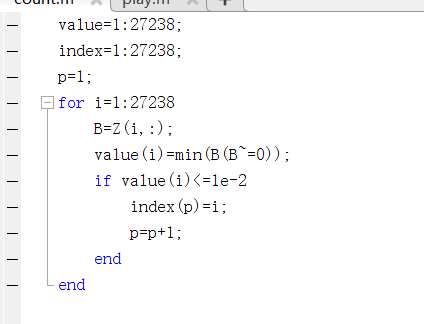
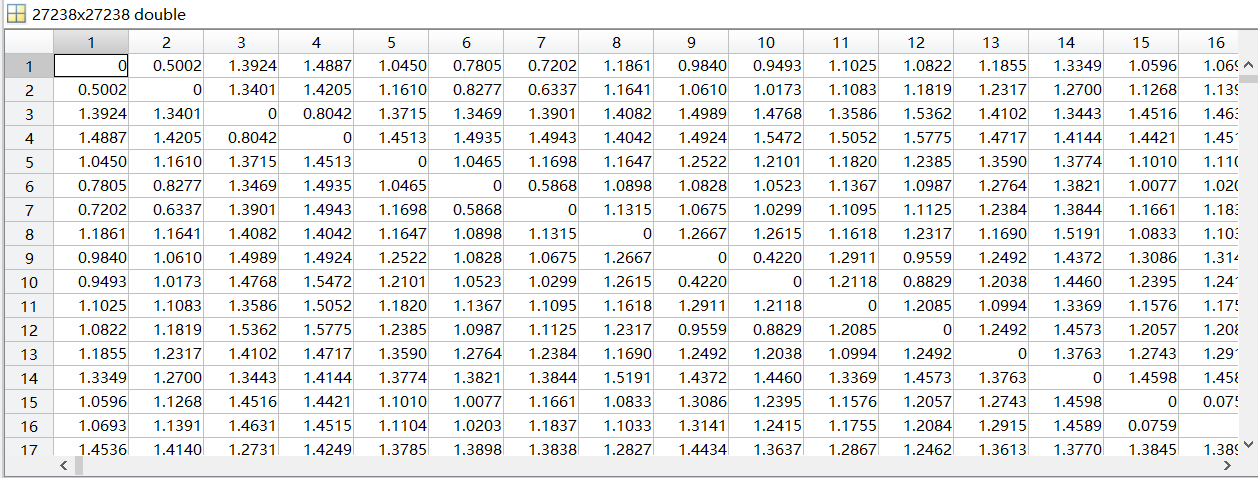 那么大的矩阵,怎么进行分析!!,只能硬着头皮通过写matlab代码,将矩阵中每行的最小值(非零)提取出来,这样就能得到27000多个最小值,然后再通过这27000个最小值进行筛选,因为本次实验主要看一下效果所以没有注意到那么多的细节,先把最小值求出来先看看。 然后我将最小值又进行了划分,论文中说他们的想法是如果距离小于
那么大的矩阵,怎么进行分析!!,只能硬着头皮通过写matlab代码,将矩阵中每行的最小值(非零)提取出来,这样就能得到27000多个最小值,然后再通过这27000个最小值进行筛选,因为本次实验主要看一下效果所以没有注意到那么多的细节,先把最小值求出来先看看。 然后我将最小值又进行了划分,论文中说他们的想法是如果距离小于1e-8就认为他们是克隆的代码,然后我以这个为分界线进行了筛选,发现只有5对符合要求,最终的结果在最终结果那里进行展示。求取最小值代码:
- 按照
- 实验结果:
- 当判断距离为1e-8时(5对)
- 当判断距离为1e-4时(75对)
- 当判断距离为1e-2时(800多对) 通过观察主要分为以下几个类型:
- 函数重载和相似函数(在同一个文件中)
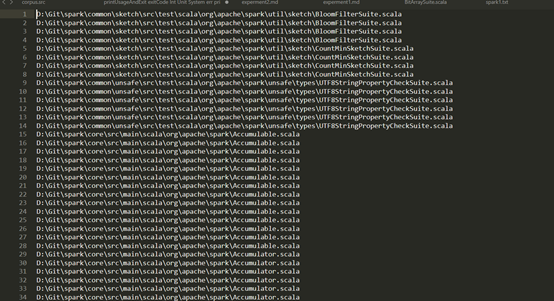
(5对)
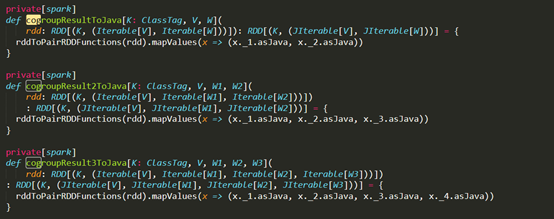
(800多对)
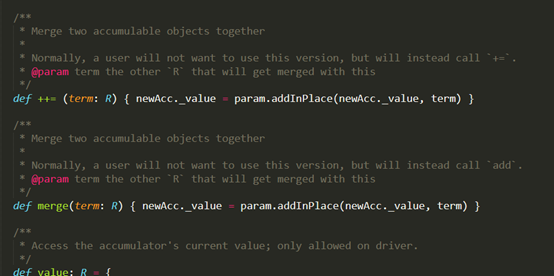
(75对)
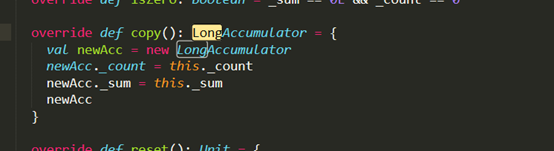
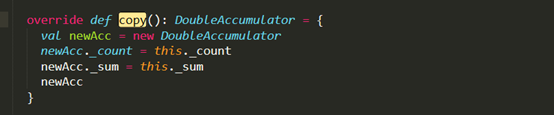
(75对)
D:\Git\spark\core\src\test\scala\org\apache\spark\deploy\master\MasterSuite.scala
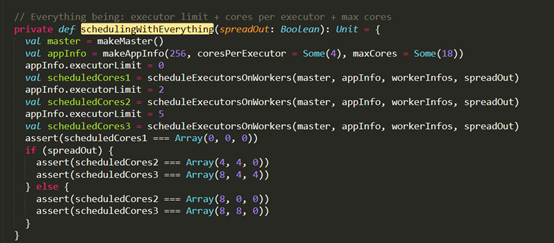
D:\Git\spark\core\src\test\scala\org\apache\spark\deploy\master\MasterSuite.scala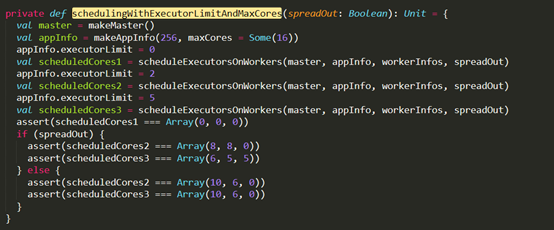
(75对) - 父子继承关系或者同时继承同一个父类的子类之间(不同文件)
D:\Git\spark\core\src\main\scala\org\apache\spark\scheduler\DAGScheduler.scala (父类)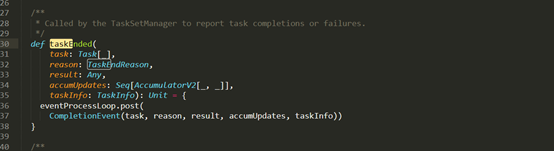
D:\Git\spark\core\src\test\scala\org\apache\spark\scheduler\TaskSetManagerSuite.scala (子类)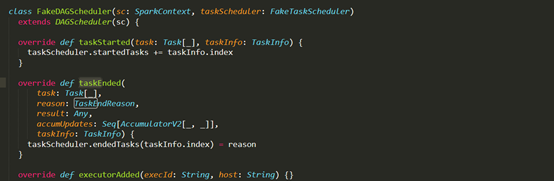
(75对)
D:\Git\spark\core\src\test\scala\org\apache\spark\scheduler\SparkListenerWithClusterSuite.scala
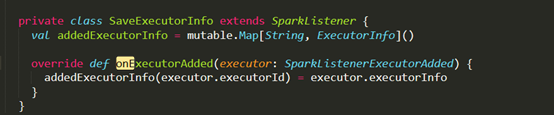
D:\Git\spark\core\src\test\scala\org\apache\spark\deploy\LogUrlsStandaloneSuite.scala
 (800对)
(800对) - 相似或者相同的函数(不同文件)
D:\Git\spark\core\src\main\scala\org\apache\spark\util\collection\PrimitiveKeyOpenHashMap.scala
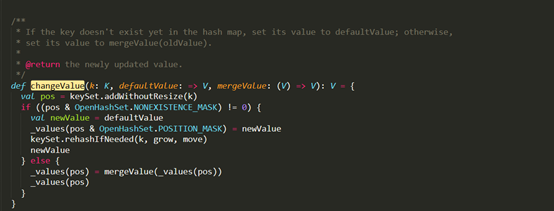
D:\Git\spark\graphx\src\main\scala\org\apache\spark\graphx\util\collection\GraphXPrimitiveKeyOpenHashMap.scala
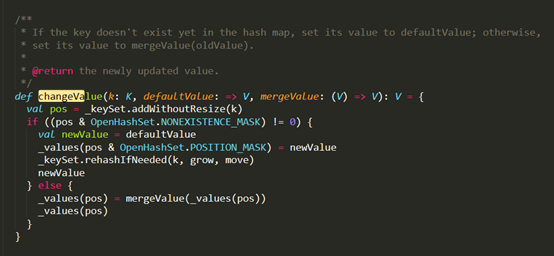
(75对)
D:\Git\spark\core\src\main\scala\org\apache\spark\deploy\history\HistoryServerArguments.scala
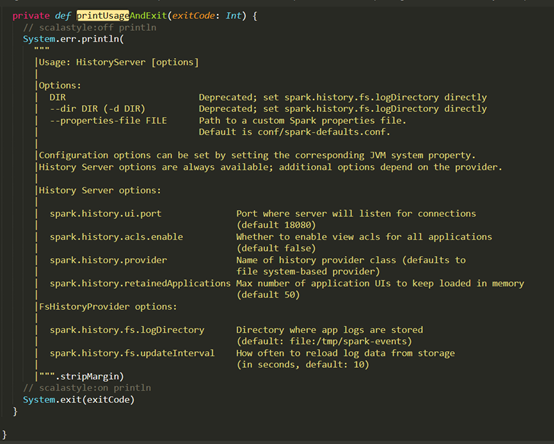
D:\Git\spark\core\src\main\scala\org\apache\spark\deploy\worker\WorkerArguments.scala
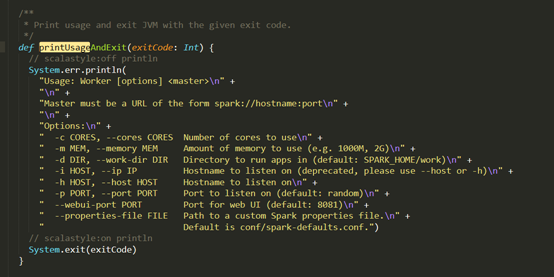
(75对) - 不像是克隆的函数(我的观点)
D:\Git\spark\core\src\main\scala\org\apache\spark\status\LiveEntity.scala
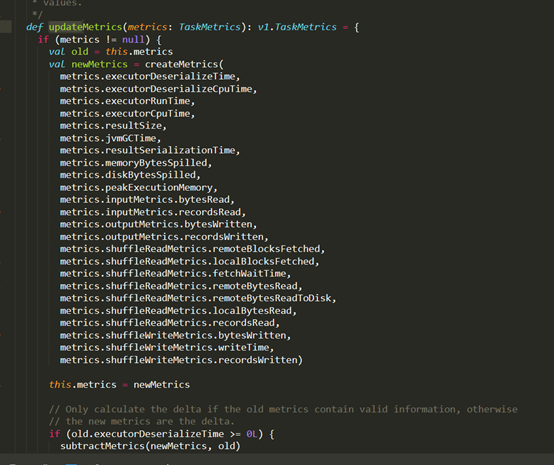
D:\Git\spark\core\src\main\scala\org\apache\spark\status\LiveEntity.scala
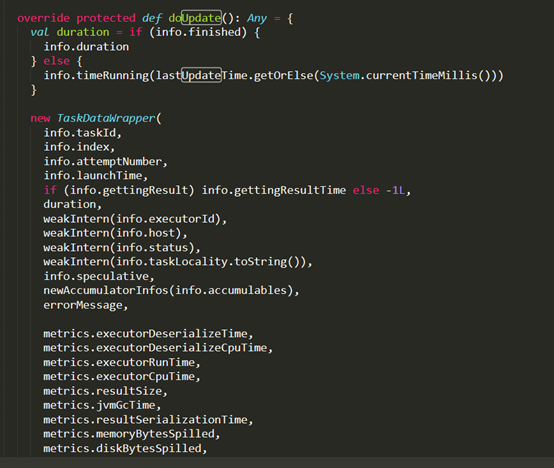
(75对)
- 函数重载和相似函数(在同一个文件中)
- 实验总结: 由于时间和人手有限,现在只是对这几个结果进行了分析,还有很多对都没有看,之后找时间看看还有没有其他类型,或者老师可以分配几个人帮我看看。
- 附录:
在得到结果以后,这是忘了如何去找源文件,这里我在原来的parse的基础上加上了一个统计样本所在的文件的文件,通过行数来查找对应的文件,感觉很费时费力。