
简单代码克隆检测七(数据分析)
Published:
本博客主要对跑出来的clone对进行打标签和统计数据
提取克隆对源代码
上次开会的吴老师建议我们用代码根据id来查找源代码,我感觉很有道理,人工筛选的话费时费力,随意我直接在原来的提取AST node的代码上加了根据id查找源代码的功能。
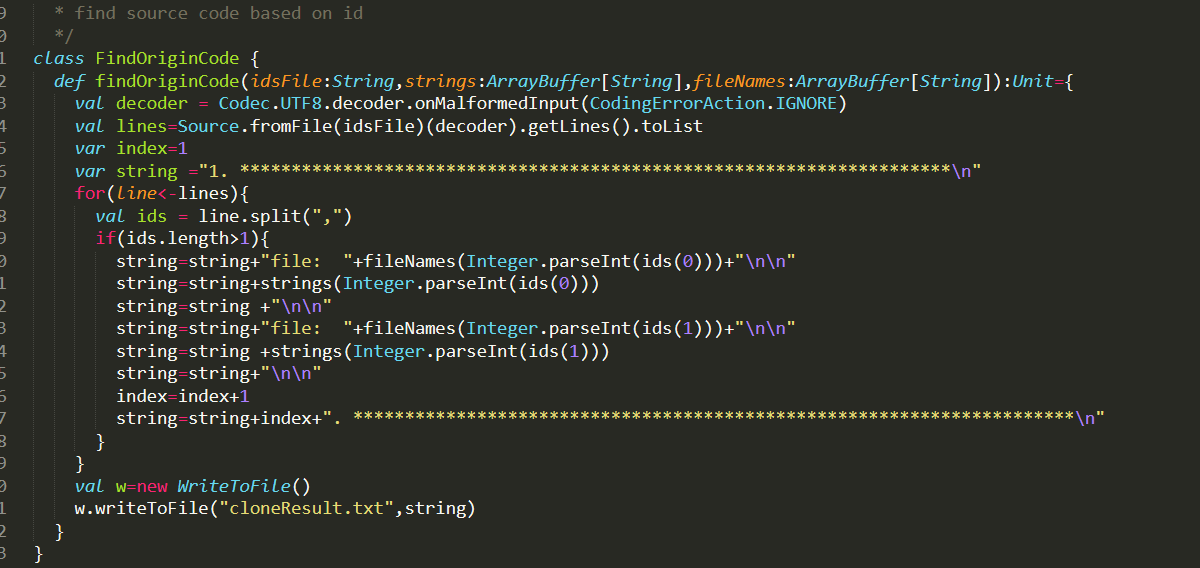
最终的提取的数据类似于:
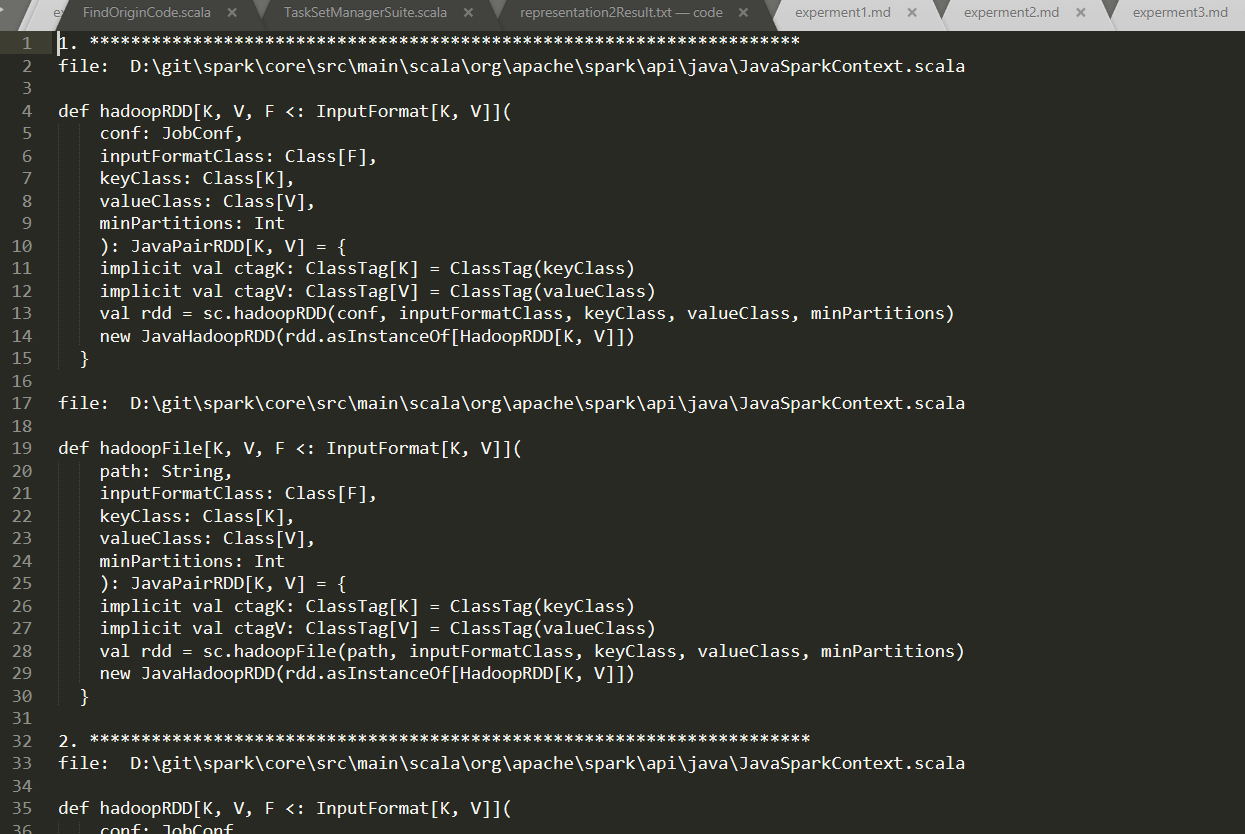
对提取的克隆代码进行打标签
这里我们找了三个人负责为每个克隆对打标签,这里要感谢何学弟、段学妹、浦帆的帮忙,打的标签的标准是根据论文中的克隆的四中类型判断标准进行,用1,2,3,4分别代表类型1,2,3,4。0代表该克隆对不属于克隆,最后根据投票制选出我们认为最终的克隆类型,我主要负责统计representation1提取的代码对和representation2提取的代码对的交集和差异集。
打标签的数据
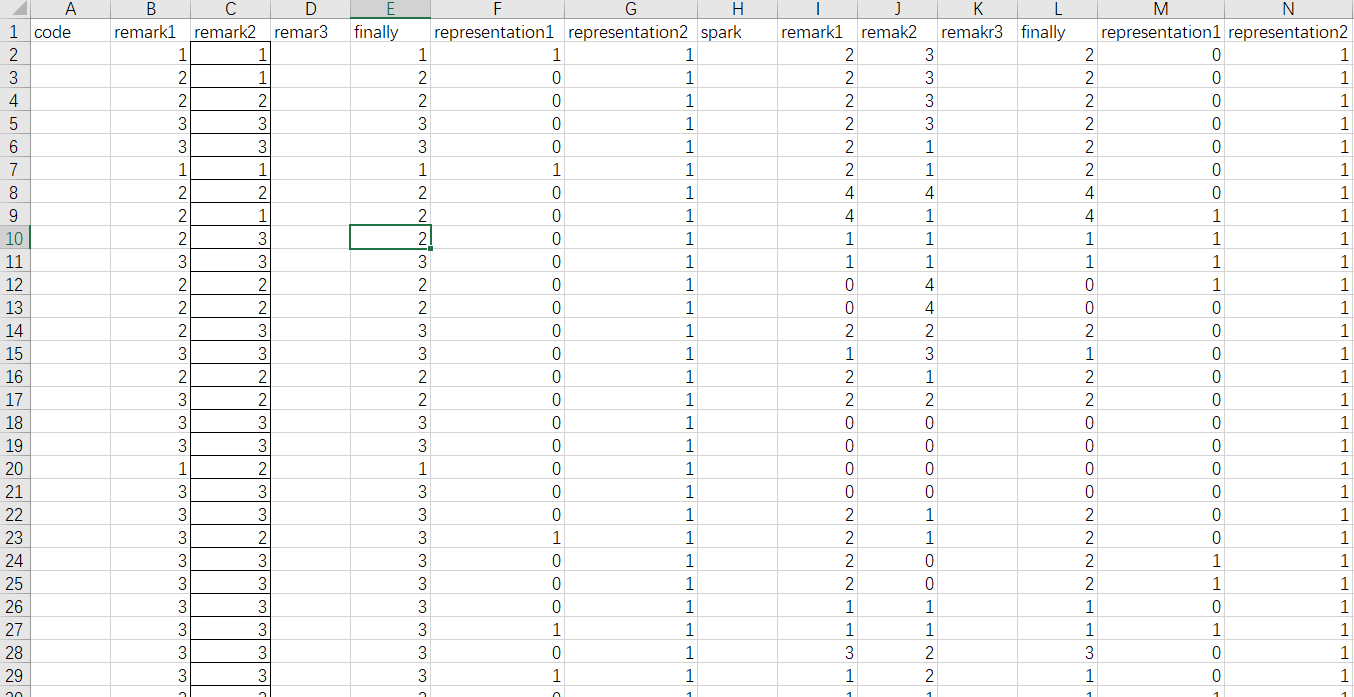
数据统计
| Project | Type I | Type II | Type III | Type IV |
|---|---|---|---|---|
| code | 13 | 93 | 89 | 0 |
| spark | 106 | 176 | 71 | 5 |
code:
|Representations|Type I|Type II|Type III|Type IV|
|:-:|:-:|:-:|:-:|:-:|:-:|
|Representation1|14|6|4|1|
|Representation2|13|93|89|0|
representation 1 提取的克隆对 并不是都是 Type1的,而且按理说representation2提取的克隆对应该包括所有的representation1提取的数据,但是code里面有两个没有识别出来,spark里面有6个没有识别出来,而且还是Type 1,对与这个结果还需要详细的分析。