
简单代码克隆检测二(AST node)
Published:
今天主要将论文中所说第二个特征 AST 节点类型提取出来,然后输入到模型中进行了验证
- 实验思路:
- 按照论文的思想,第二特征主要用一个
high level的特征来体现代码,这个特征就是用AST节点的类型来表示,比如:Defn.def是方法的类型,Term.for是for语句的类型等等这些,其主要的目的就是让我们处理的方法更加抽象,解决变量名改变(第二种类型clone)克隆方面有着很好的效果。在提取数据的时候作者做了一点小的改变,并没有将所有的节点的类型都作为特征,而是除去了SimpleName,QualifiedName(java)两个类型的节点,相应的我将Scala语言中的Term.Name,Type.Name两个节点的类型也进行了忽略,这样做的主要原因是,第一,这两个节点已经属于较低层次的特征,会与我们之前提取的第一个(identifiers)特征重复,第二是,两节点的数量很多,在java中有将近46%的节点类型在这两个类型之间,所以就直接将这两个节点直接去掉。 - 数据提取完以后就按照之前的做法输入到AutoenCODE中去进行训练,观察效果,并与第一次实验做了一下对比。
- 按照论文的思想,第二特征主要用一个
- 实验步骤:
- 提取
AST节点类型,只要在非叶子节点的visitor中加入相应的统计的代码即可。
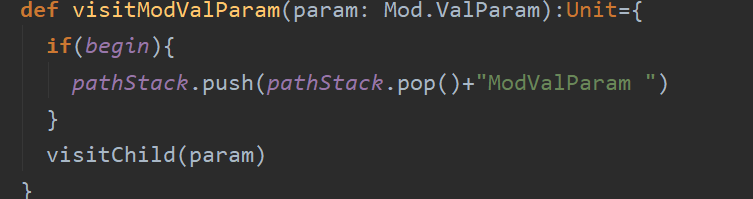
最终得到的数据的结果如图所示:
- 对提取的数据进行
wordembeddings,产生相应的词向量:

- 将词向量输入到AutoenCODE模型中进行训练,最终得到距离矩阵:
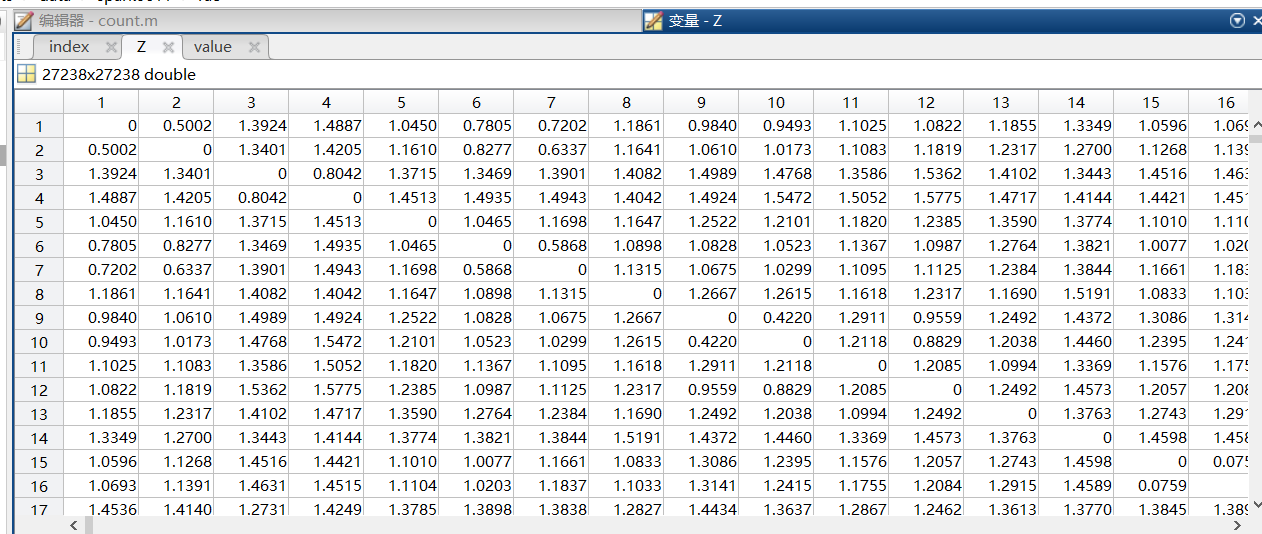
- 对距离矩阵进行统计,上次实验中只是统计了没行中非零的最小值,所以数据量很小,这次我遍历了整个矩阵,求出距离小于
1e-16(上次实验说错了,1e-8是对类级的clone进行判断,这个其实是根据不同的项目来设置不同的值,这里我们暂且先按照论文中的数据俩进行实验)的所有clone对的行数,然后依次找出相应的代码进行比较,与上次的实验结果进行比较。
- 提取
- 实验结果:
- 对于第一次实验,我前面已经说过了,统计的阈值设置成
1e-16并且统计所有的数据发现一共有大概有2万条数据,也就是有大概2万对克隆对是通过第一个特征发现的,具体是不是克隆对需要后期人工进行处理,工作十分艰巨。
提取克隆对的代码:
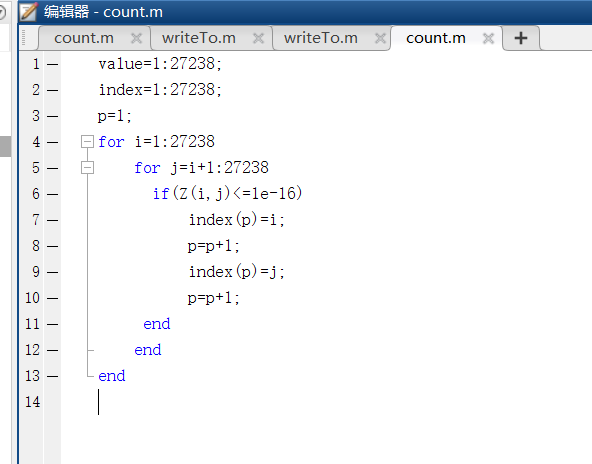
结果:
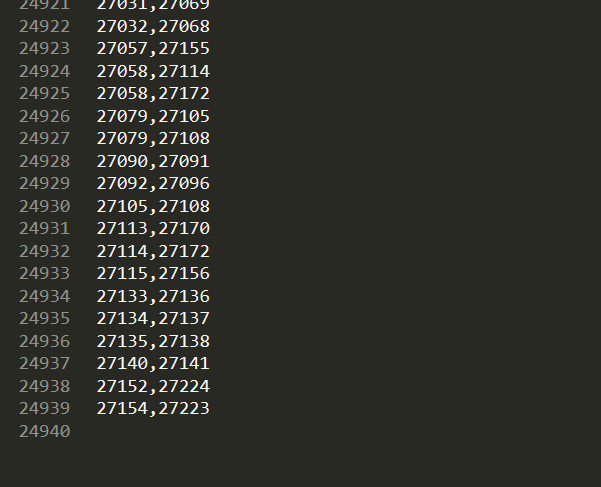
通过赵俐俐学姐目前的统计的数据来看,这两万条数据中的克隆对是完全一模一样,属于判断是否为clone的第一种类型。例子: D:\Git\spark\core\src\main\scala\org\apache\spark\Accumulable.scala

D:\Git\spark\core\src\main\scala\org\apache\spark\util\AccumulatorV2.scala
- 第二次实验得到的结果更让我吃惊,大概有30w克隆对:
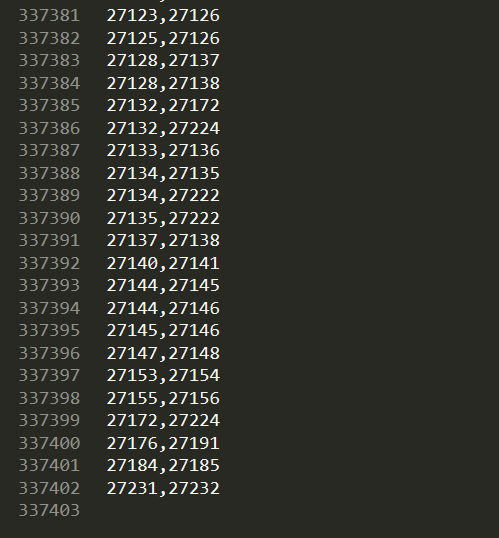
对这30w数据进行简单的分析:- 第一个特征里面的数据基本上都包含在内
- 其次是一些变量名不同,但具有相同结构的函数被识别出来了:
D:\Git\spark\core\src\main\scala\org\apache\spark\Accumulable.scala
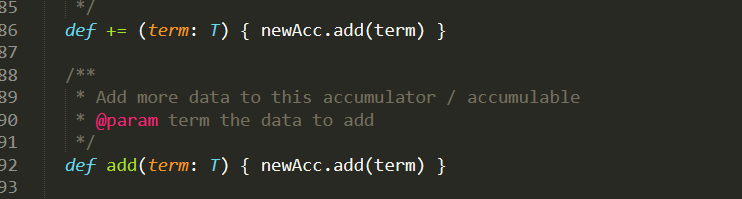
- 但是其中大多数的数据都是一些判断错误的数据,我对这些数据进行了简单的观察,发现他们有一个特点,就是样本数据短小,往往就几个简单的语句:
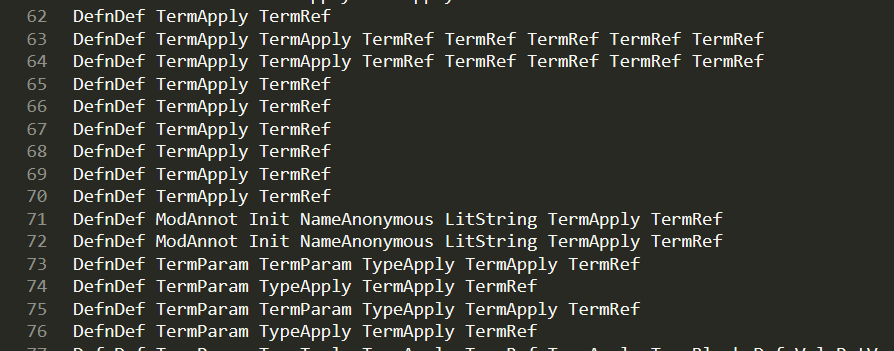
而数据量小,就会导致很多差别很大的函数被误判为代码 clone:
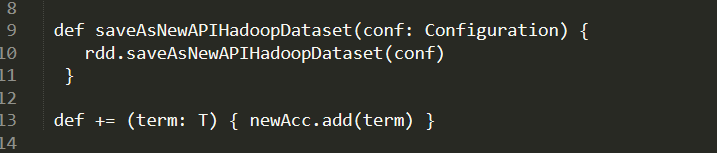
而一些代码很长的判断则更像是代码克隆:
D:\Git\spark\core\src\main\scala\org\apache\spark\Aggregator.scala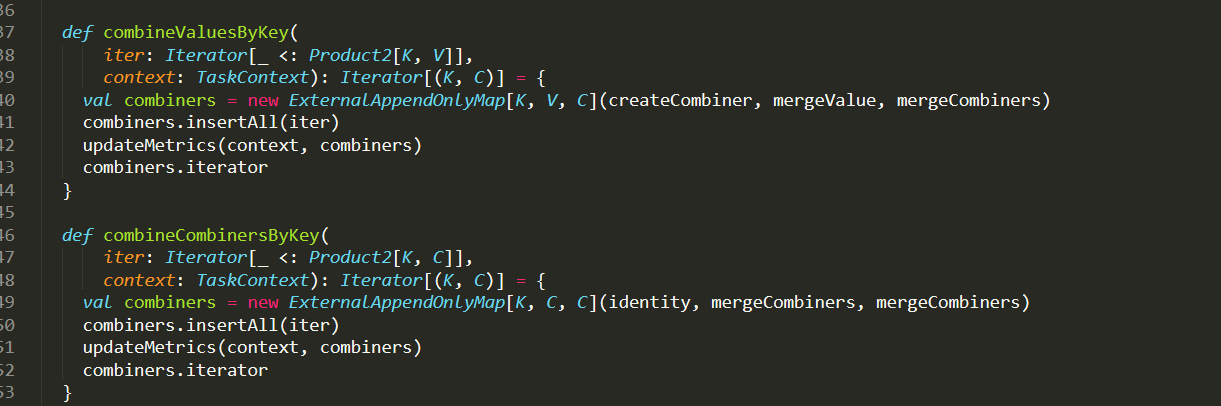
- 对于第一次实验,我前面已经说过了,统计的阈值设置成
- 下一步工作:
- 与俐俐学姐统计并观察得到的clone对(第一个特征)
- 询问并查找如何去除第二种类型的过多的错误数据
加油!!!