
简单代码克隆检测(三)(精简数据)
Published:
今天主要是解决昨天的问题,第二个特征提取的clone对过多,导致很多较短的方法也被误认为是clone对,今天做的实验室将方法的长度进行了限制,
- 实验准备:
- 昨天老师提及到了一点
传统的clone detection一般只考虑长度10行以上的代码片段,恰好scala meta 提供了position属性可以供我们进行筛选,但是scala meta 提供的并不是行数,而是这个方法中有多少的字,下面简单展示几个例子,让我们了解一下方法的具体规模信息:- 200 字节:
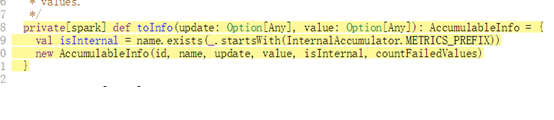
- 300字节:
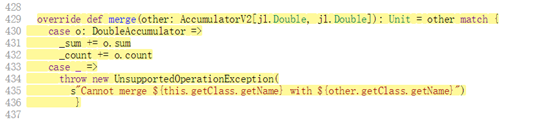
- 400字节:
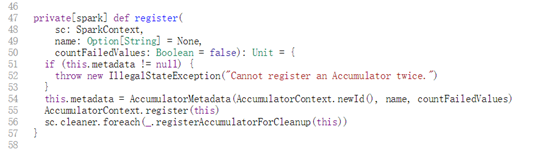
- 500字节:

- 600字节:

- 1000字节:
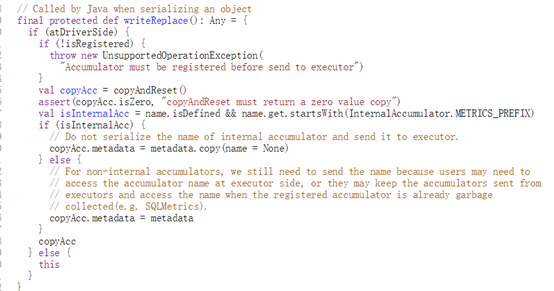
然后我查看了spark的几个scala文件,发现大多数的方法的长度都很小,都在200-300之间,但是为了获取较为大的函数,我选取了500字节作为阈值进行筛选。代码:
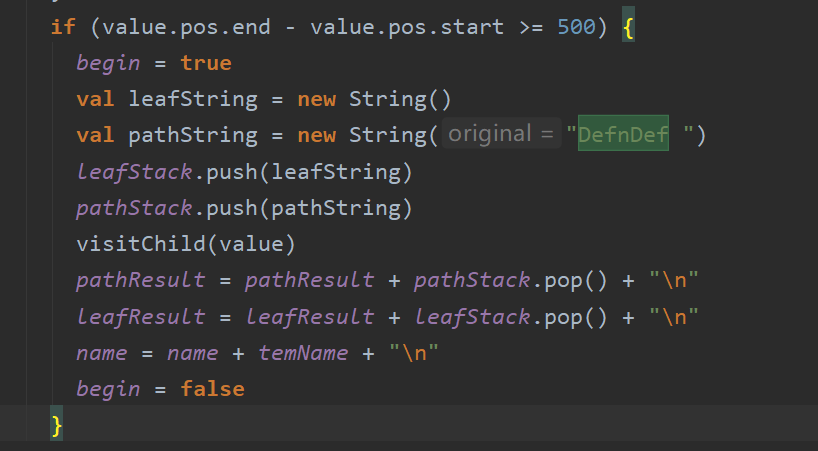
- 200 字节:
- 昨天老师提及到了一点
- 实验步骤:
- 首先,提取
leaf node和path node数据,共得到5387条数据:

- 然后分别对
leaf node和path node属性进行wordembeddings然后输入到AutoenCODE,(这里提及一下,这个框架里面有几个参数,我在实验的时候并没有进行修改,后续实验的时候需要研究一下,修改超参数观察数据变化。)
- 首先,提取
- 实验结果:
leaf node:- 距离矩阵:
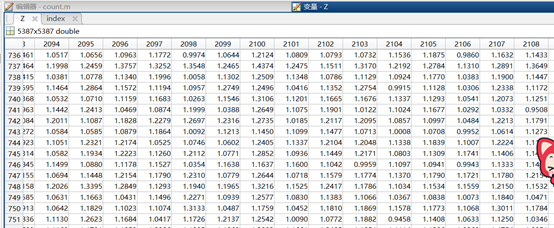
- 提取的距离小于
1e-16的克隆对:
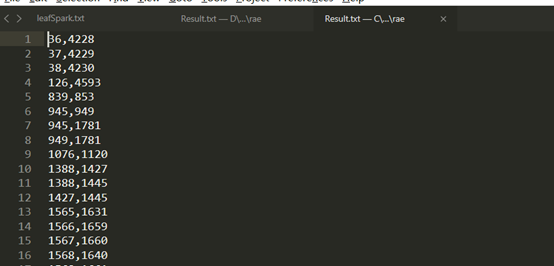
总共提取出了114对代码克隆对:
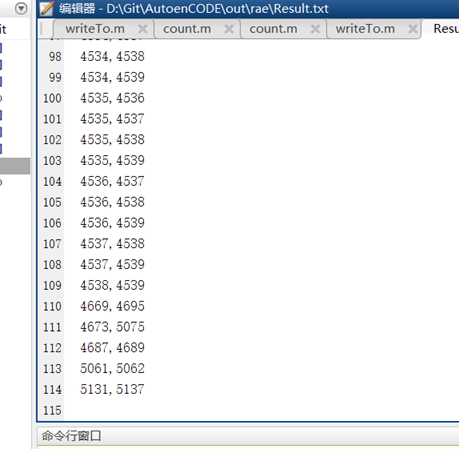
- 例子:
D:\Git\spark\core\src\main\scala\org\apache\spark\api\python\PythonRunner.scala
D:\Git\spark\sql\core\src\main\scala\org\apache\spark\sql\execution\python\PythonUDFRunner.scala
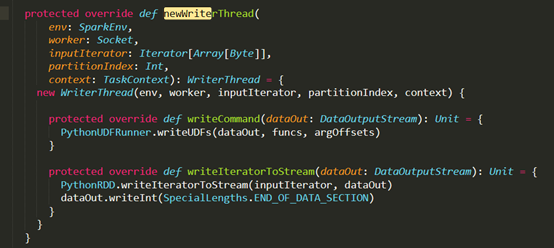
- 距离矩阵:
path node:- 距离矩阵:
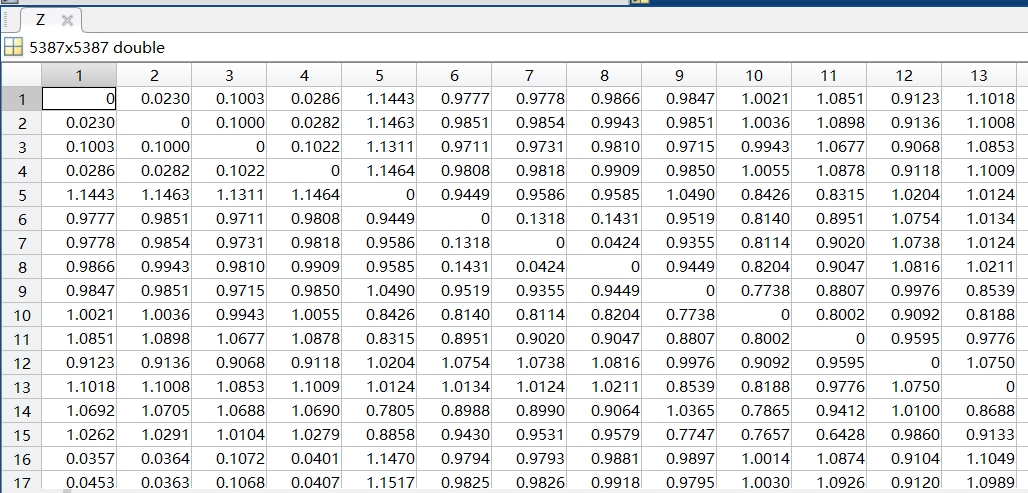
- 提取的距离小于
1e-16的克隆对:
总共提取出了185对代码克隆对:
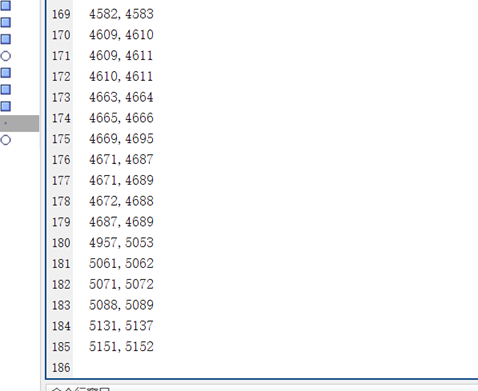
- 与
leaf node进行比较,前面我们举的两个例子是 id 为36,4228的例子,我们发现在path node的结果中不仅出现了36,4228的克隆对,还出现了36,4215的克隆对,所以这里只展示id为4215的代码,进行对比:
path node:
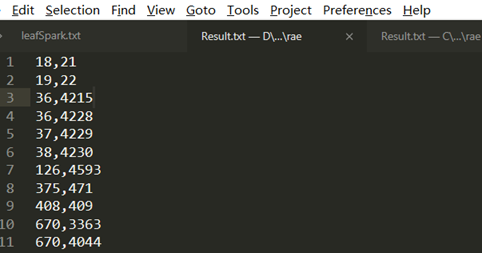
leaf node:
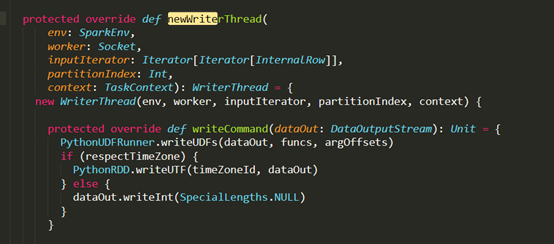
对别代码:
D:\Git\spark\sql\core\src\main\scala\org\apache\spark\sql\execution\python\ArrowPythonRunner.scala
- 距离矩阵:
- 实验总结:
- 在我看来
path node是在leaf node的基础上进行的扩充,其中leaf node属性提取的克隆对作为主要研究研究对象,path node仅提供辅助分析的作用。 - 本次实验代码长度的阈值设置不是很巧当,有昨天的2w条数据变为今天的100多条数据,中间很多小的代码块也可能存在代码克隆。
- 对于设置代码长度的这个方法,我的想法是只针对
path node特征进行操作,因为我们昨天已经发现了,对于leaf node提取的2w条数据发现,基本上代码都是相同的(代码clone的第一种类型),不管是长代码还是短代码,只要全部相同就有很大的可能是代码克隆,所以设置代码长度阈值可以只实施在path node特征上,毕竟起到的是补充辅助的作用。
- 在我看来
加油!!!