
简单代码克隆检测(四)(提取二进制数据)
Published:
按照Michele等人的论文,加下来应该提取的特征是流程图和二进制特征,但是由于流程图提取的过程中出现很多问题,所以今天我先把二进制代码特征提取看了下。
实验背景:
获取scala文件编译的class文件:
之前在提取第一、二中特征的时候,没有用到class文件,这时突然发现源码里面没有class文件,咨询了一下老师,说有两种方法,一个是编译源码,得到最终的class文件,另一种直接找jar包,jar包里面有已经编译好的class文件,果断采取第二种方法,第一种方法太麻烦,而且编译其他人的程序来说没有特定的说明文档很难成功,于是在网上下载了spark相应的jar包,解压缩后查看里面的class文件。 spark项目用到的所有的jar包:
解压spark-core.jar进行试验,由于jar过多,我就直接选了一个spark-core来进行试验。

在这里我发现了一个问题,那就是一个scala文件生成的class文件不止一个,他可以生成2个甚至6、7个,然后我上网查了一下,网上也没有多靠谱的解答,只是有人做了实验,本名的class文件里面的方法是全的,包含$的class文件在运行的时候本名的class文件会调用它。
我自己做的实验提取的两个class文件的内容:
Accumulable.scala源文件:
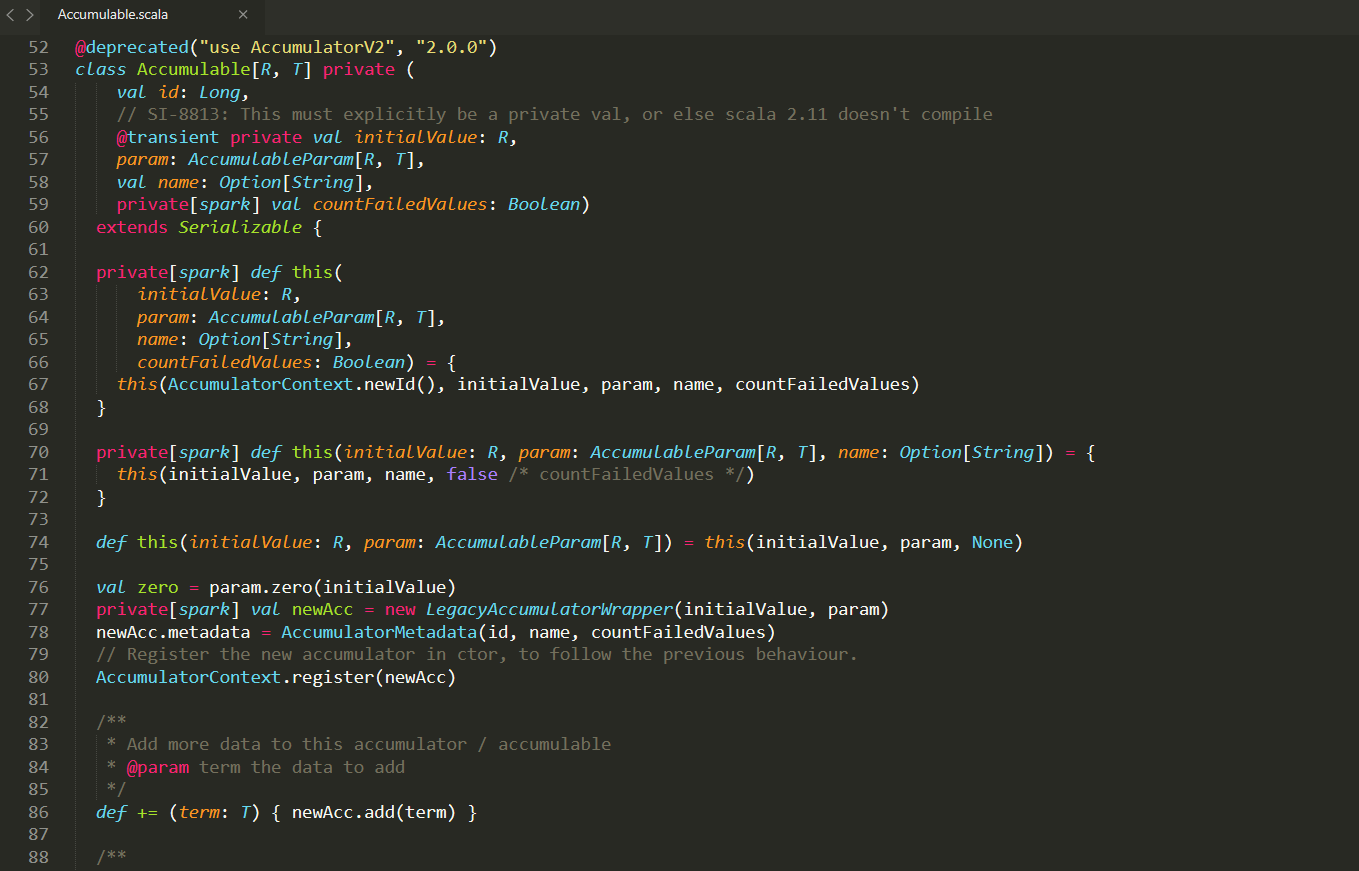
Accumulable.class解析出来的文件:
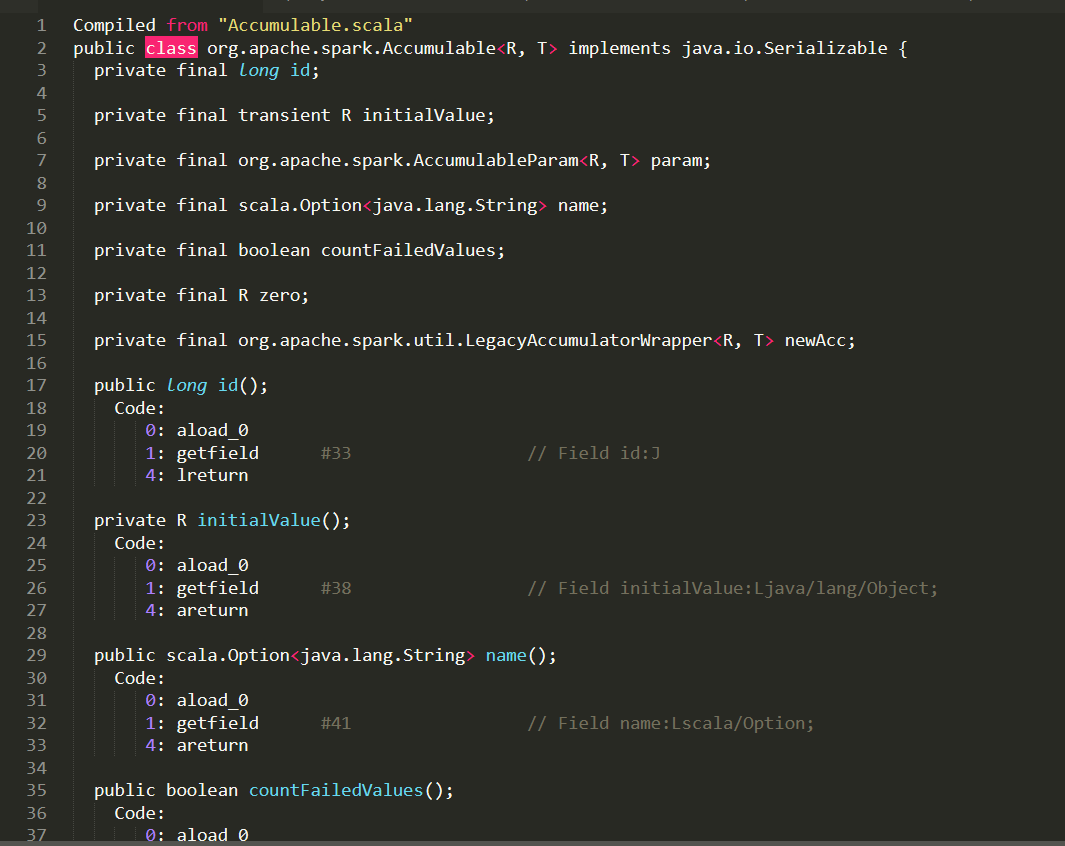
Accumulable$$annonfun$1.class解析出来的文件:
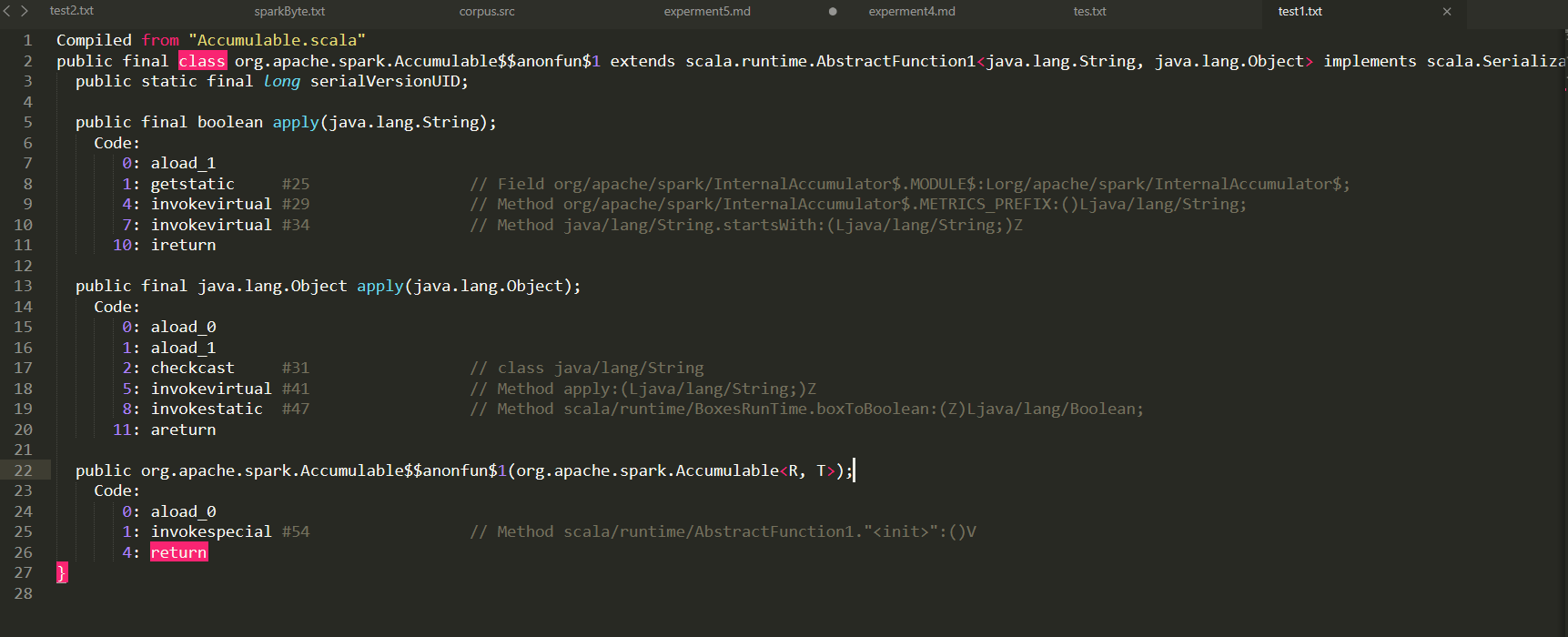
而且经过跑出来的数据来看,大多数衍生出来的class文件都有一个apply()函数,但是源文件(scala)里面并没有这个函数,基于此,我先暂时提取本名class里面的特征,没有提取衍生class里面的特征。
实验步骤
提取特征:
按照论文中给的方法进行试验,就是利用java的反编译工具javap来提取二进制特征:
论文提及的方法:

论文提及的方法已经给出来,但是他没有给出提取的代码,只给了一行命令行的命令,所以还得编写一个提取特征的程序,程序主要有两个部分组成:
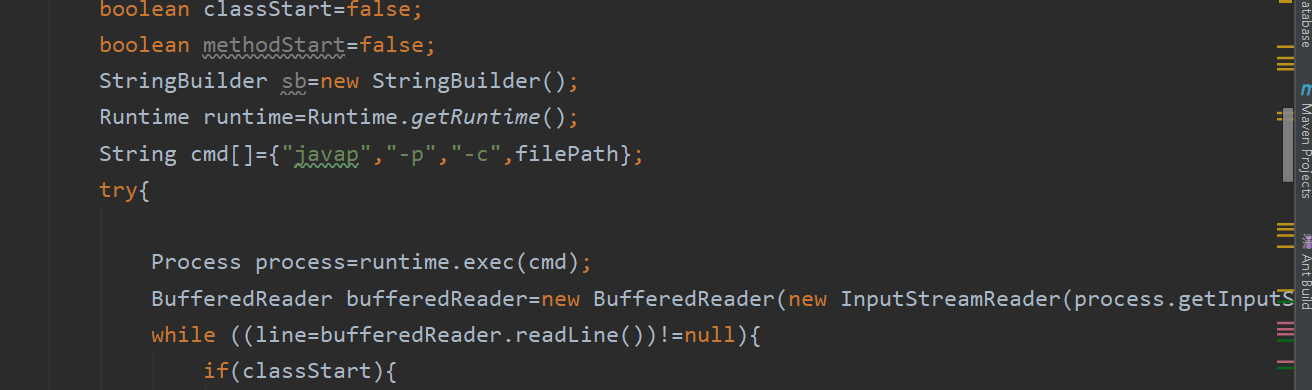
### 调用cmd,执行javap:
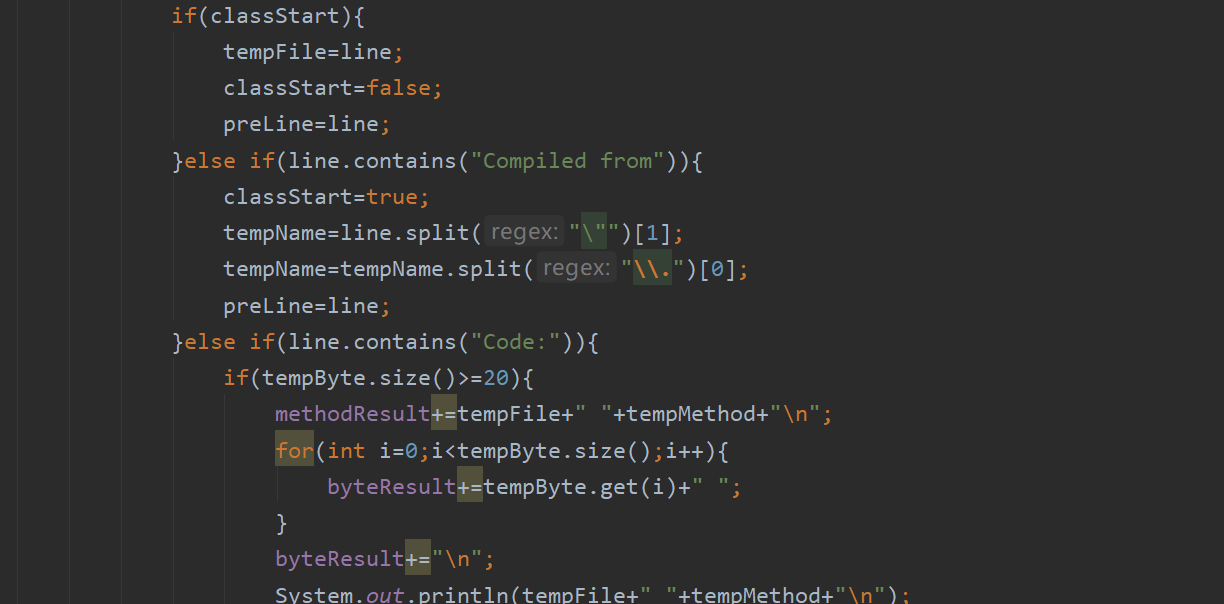
### 对返回的结果进行字符串的分割以及特征的提取:
 最终提取的数据的形式为:
最终提取的数据的形式为:

带入autoencode系统中进行训练
在本次实验中,spark-core的jar包里面一共提取了1685条数据,在这里我进行了数据筛选,低于20个词的数据都没有作为数据集,带入之前系统中进行训练,共得到630对克隆对: 总数据:
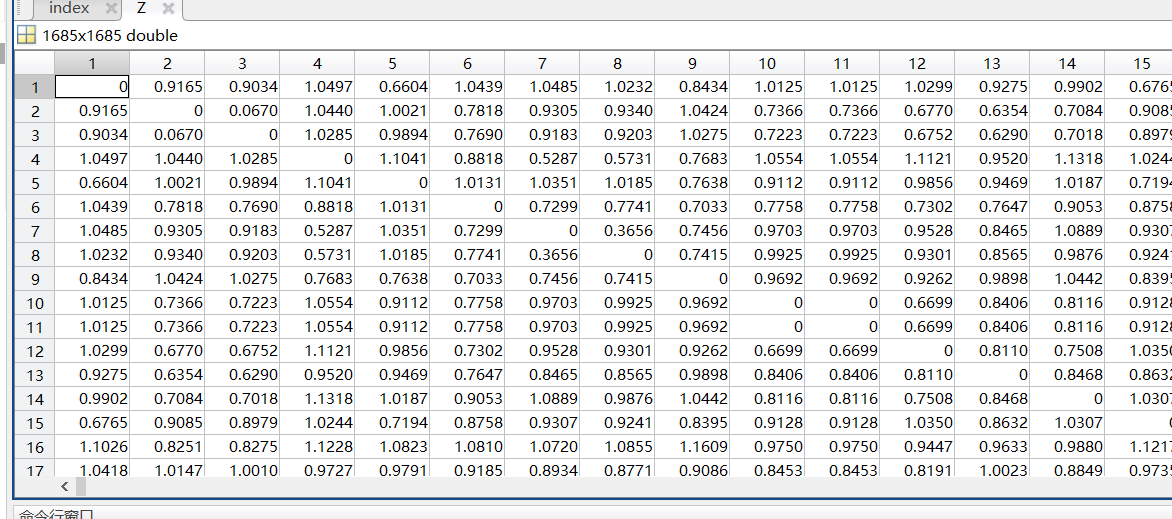
得到的clone对:
clone对的例子:
D:\Git\spark\core\src\main\scala\org\apache\spark\Accumulable.scala

D:\Git\spark\core\src\main\scala\org\apache\spark\util\AccumulatorV2.scala 
实验总结:
这次实验证明了确实可以从二进制方面来考虑判断clone,但是我没对数据进行分析,暂时还没有发现那种功能相似但是代码不一样的clone对(也就是第四种类型)。
明天争取把控制流的特征提取出来,观察一下。
加油!!