简单克隆代码检测(实验数据对比)
Published:
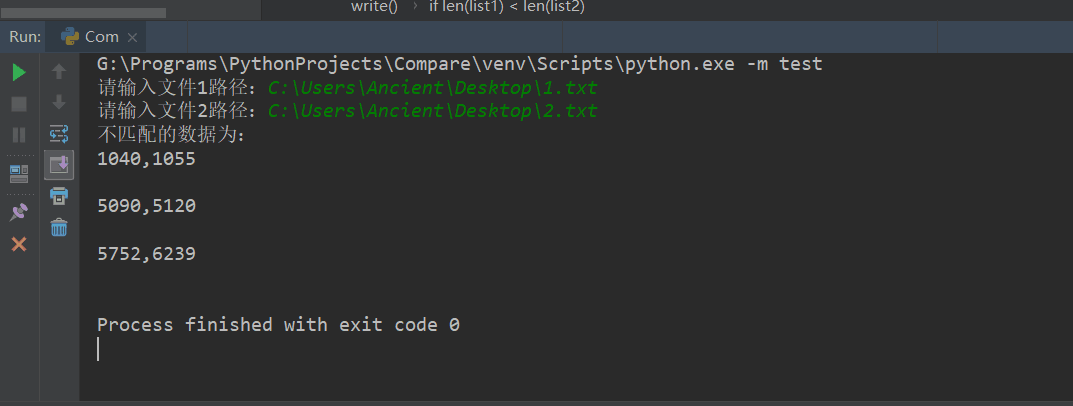
本博客主要是对上星期统计的数据不正常现象做对比实验,观察最终结果。
matlab 版本
| representation | representation 1 | representation 2 |
|---|---|---|
| 得到的克隆对数 | 123 | 324 |
通过人工统计,共发现3对representation1里面的克隆对,未在 representation2中出现。
截图:
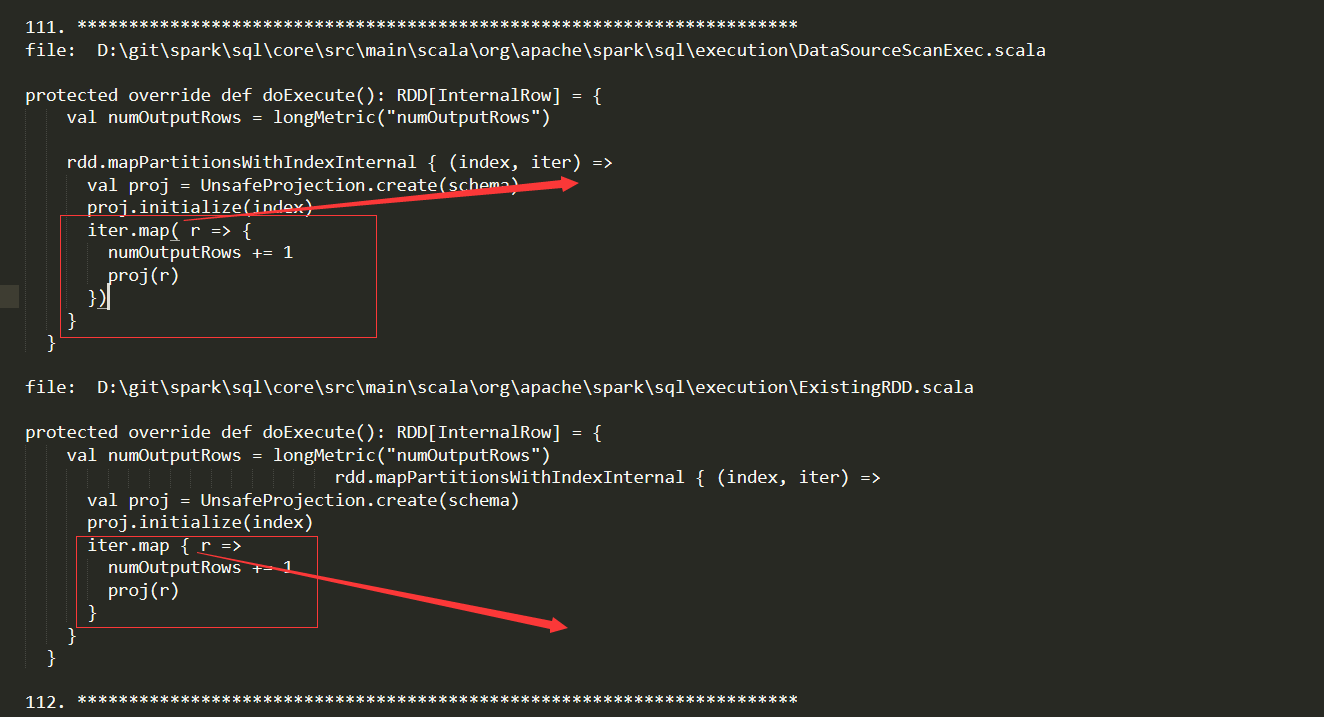
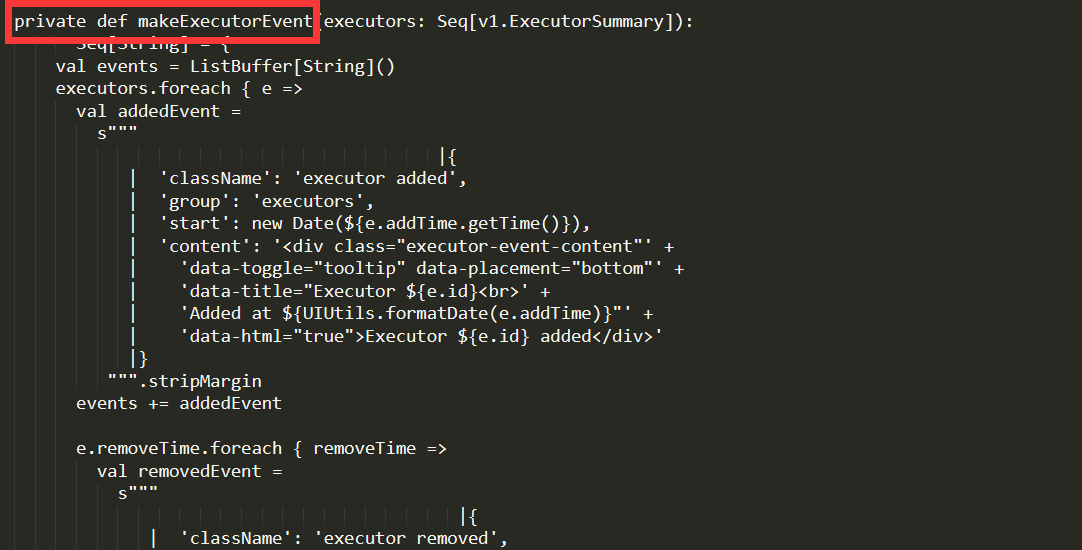
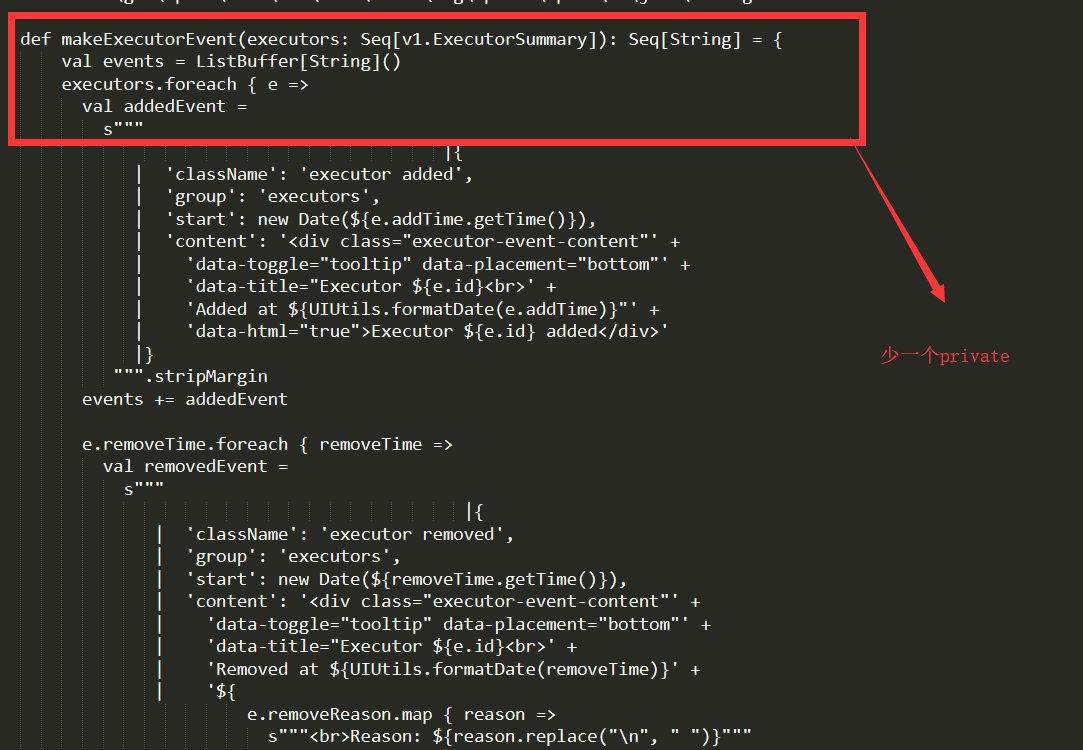
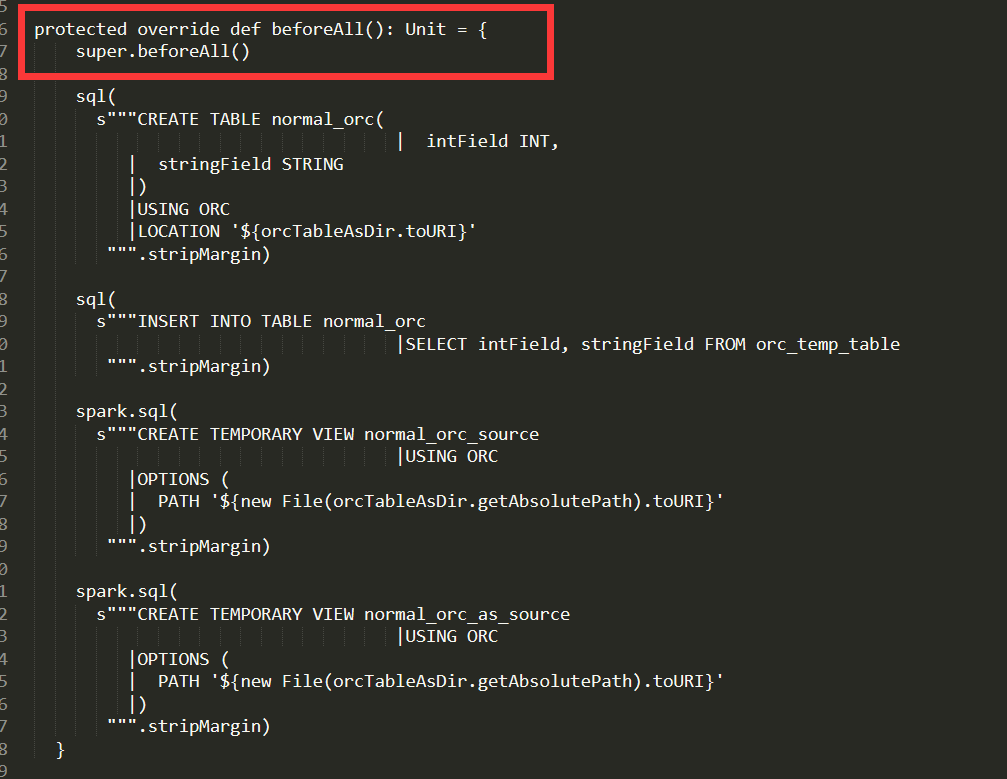
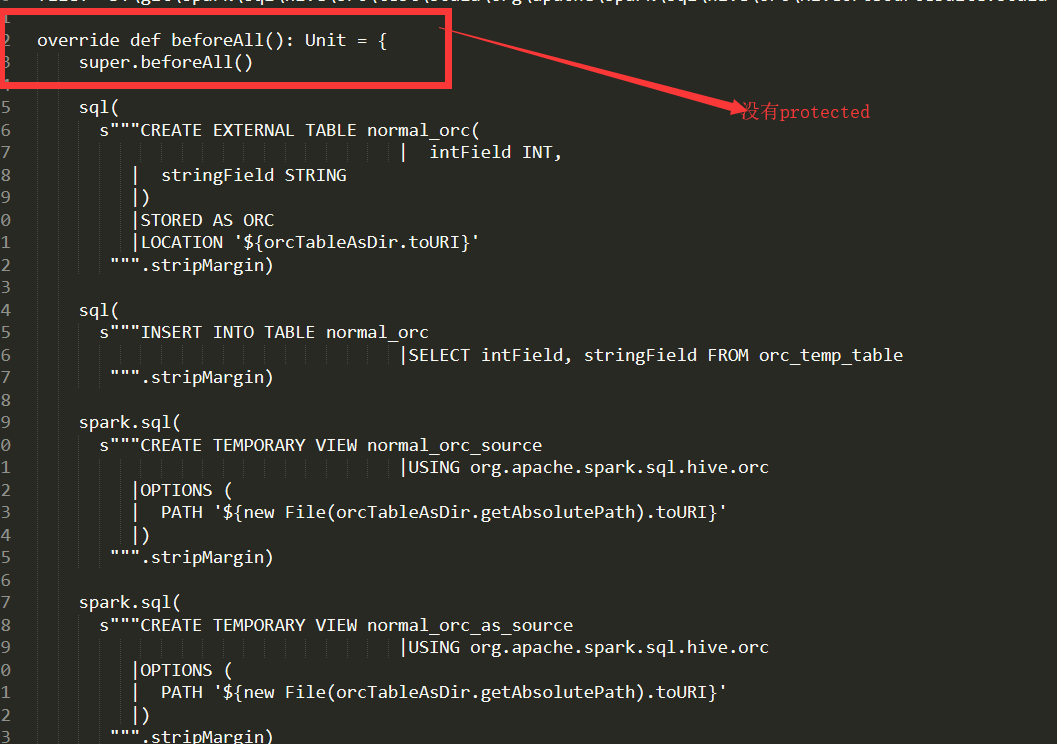
通过比较发现,这种情况是很有可能发生的,虽然他们的identifiers全部是一样的(private,protected不属于identifier),但是他们的语句(statement),就是不一样,少了一个或者两个语句,并且()和{}所表示的语句也不是一样,这就造成了我们之前出现的错误。经过统计发现这是一个正常的现象。
python 版本
阈值: 1e-16
| representation | representation 1 | representation 2 |
|---|---|---|
| 得到的克隆对 | 125 | 452 |
阈值: 0
| representation | representation 1 | representation 2 |
|---|---|---|
| 得到的克隆对 | 124 | 408 |
通过比较观察,当阈值为0的时候python版本比matlab版本representation 1多了一个样本:
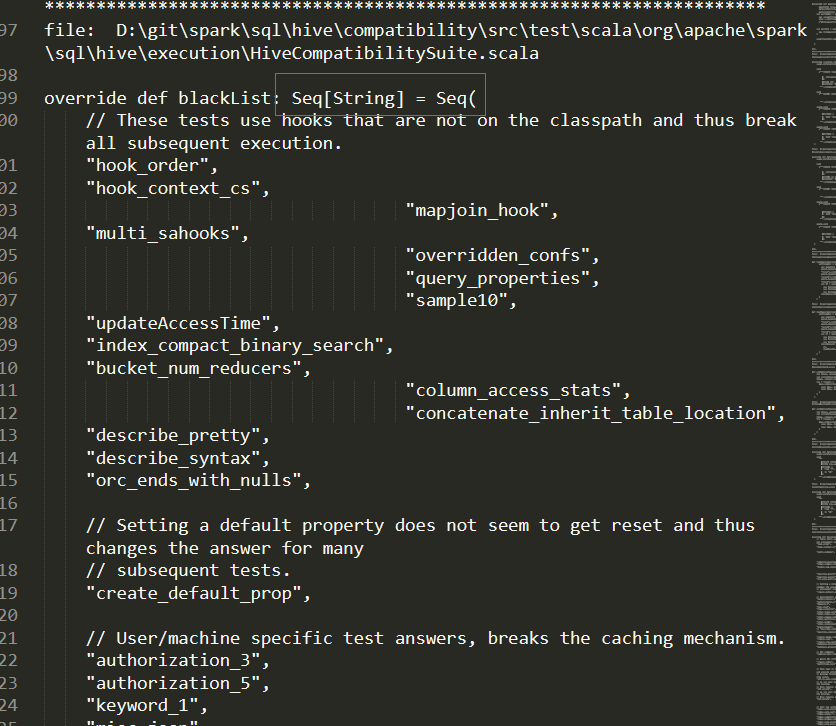
由一个函数构成的一个list,里面大概有四五十个字符串,而且每个字符串的内容不一致。
我们查看一下我们提取的representation 1的数据:
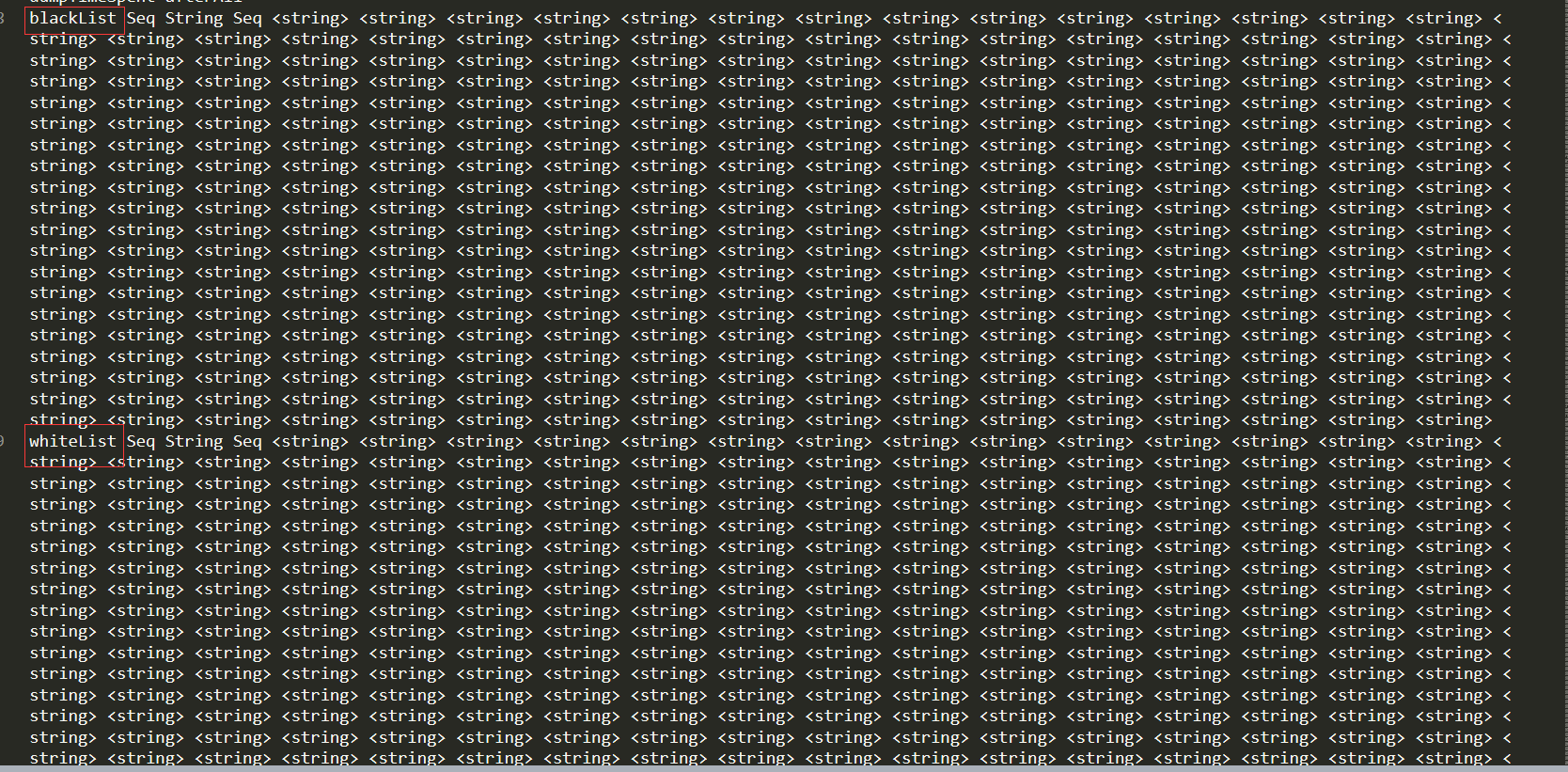
里面就只有一个词不相同,在matlab版本里面是不认为这个是相似的,但在python版本里面认为是相似的,我感觉只要是在word embedding 和 sentence embedding 的时候框架的精确度不一致,因为参数我都设置为相同的。
当阈值为1e-16的时候,多了两条数据,一条就是上面说的那个list,另一条是
也是一个词不一样(属于Type III),导致结果多了两个。
再对representation 2的结果进行分析,大多数增加的数据都属于第三种类型,就是增加或者删除一条语句,特征表现上为增加或者删除一个词。
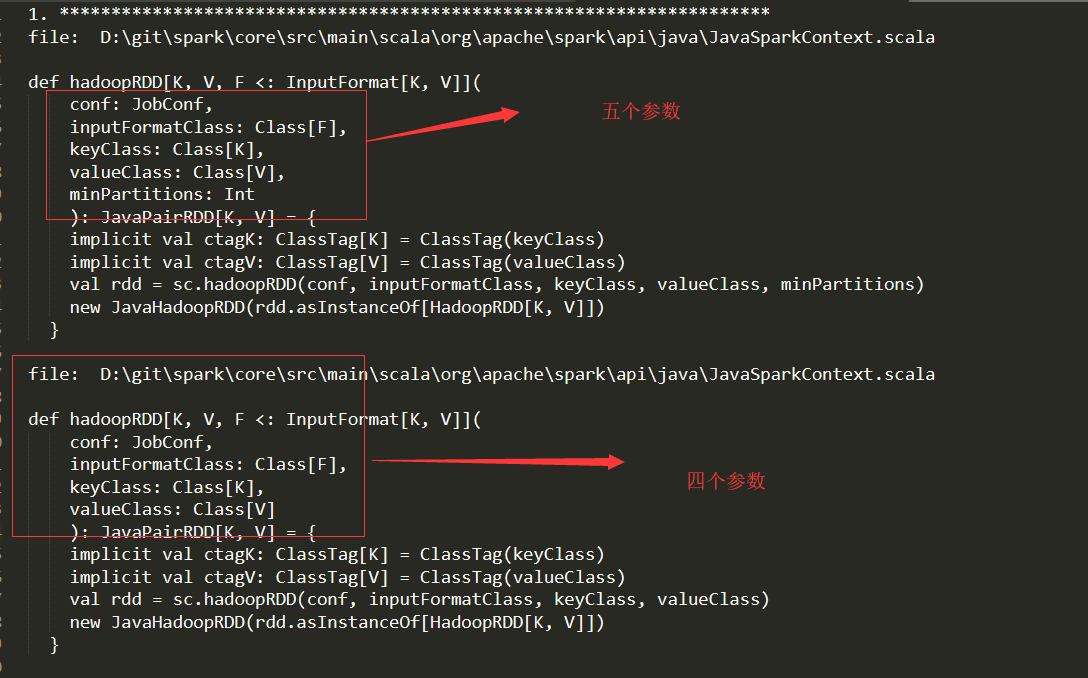
实验总结
representation 1提取出来的克隆对未出现在representation 2中属于正常现象- matlab版本框架要更加
严苛,只要有一个词不同就认为是不同的,相对而言,python版本的代码能够提出较多的第三种类型的克隆
还有,要感谢何学弟帮忙查看数据,以及写相应的工具代码。