
简单克隆代码检测(版本更新及相应bug修复)
Published:
这一周主要对项目中代码存在的问题做了一点修改,同时想了一下如何对项目运行时间进行优化
修改的bug
之前我们一直根据spark开源项目来开展我们的研究,没有跑其他的项目,这就造成了程序的不兼容性。果然通过英国那边的老师的反馈确实程序的健壮性出现了问题。于是又跑了几遍程序,修改出现的问题。
在修复的过程中,我们主要以scala语言的开源代码作为目标代码: https://github.com/scala/scala ,因为我觉得这个项目应该包含了scala语言的所有特性。 最终发现了两个问题:
- scala的一些语法spark项目里面并没有全部包含,这就导致了一些语法没有找到,被打印到了控制台,通过观察控制台输出的语句,在代码中添加之前未添加的语句类型即可。
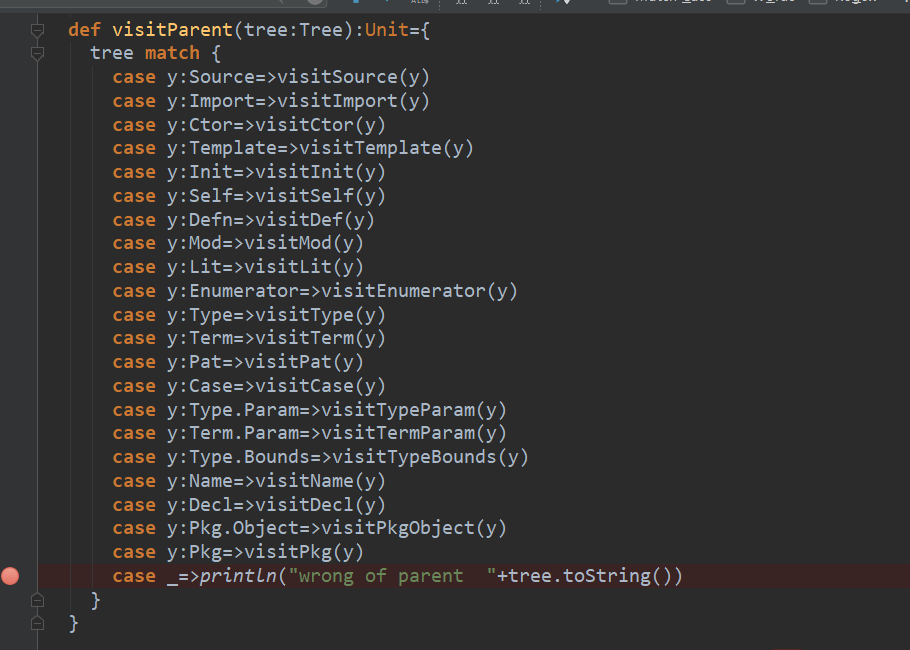
新添加的方法
- 嵌套函数的处理不完善,父函数包含的内容过少,导致错误分类。例如:
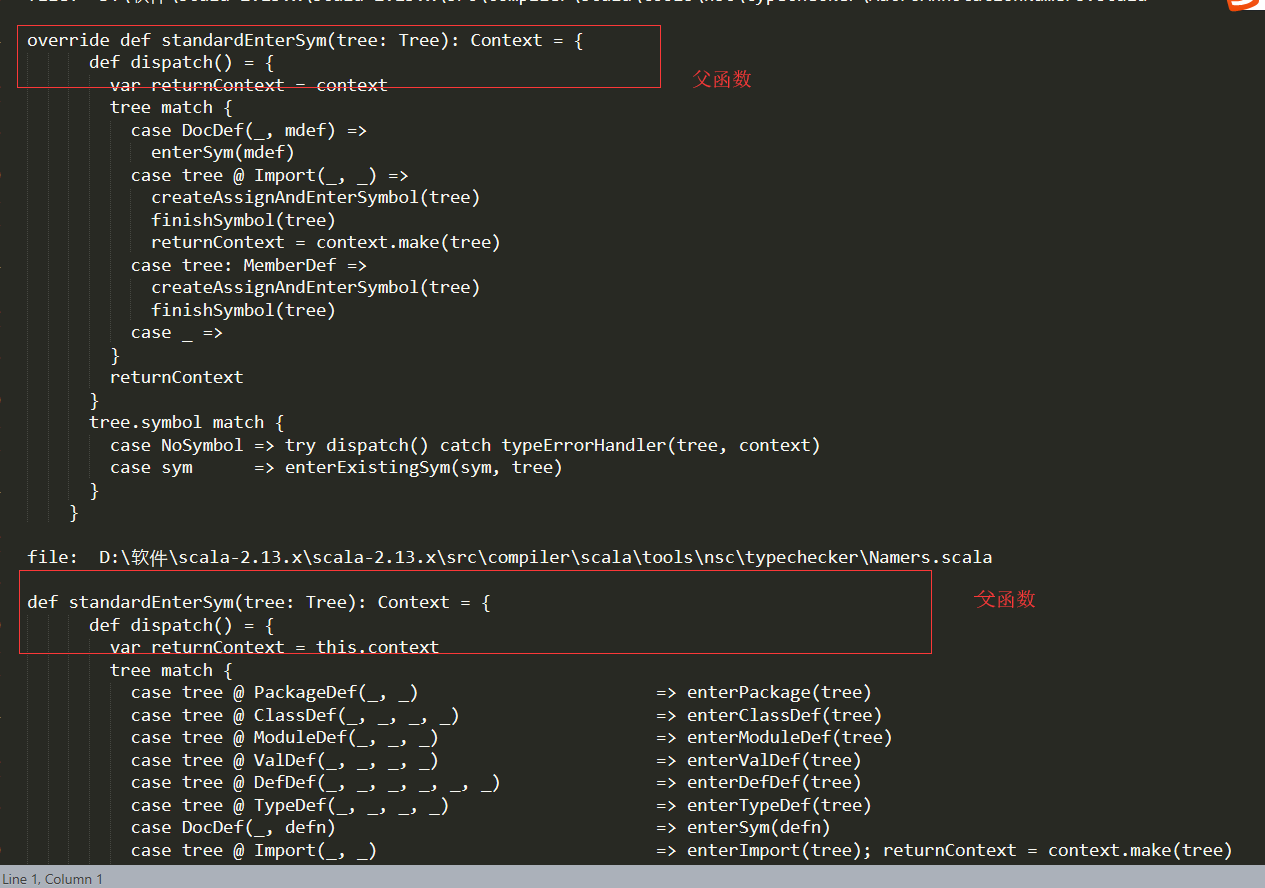
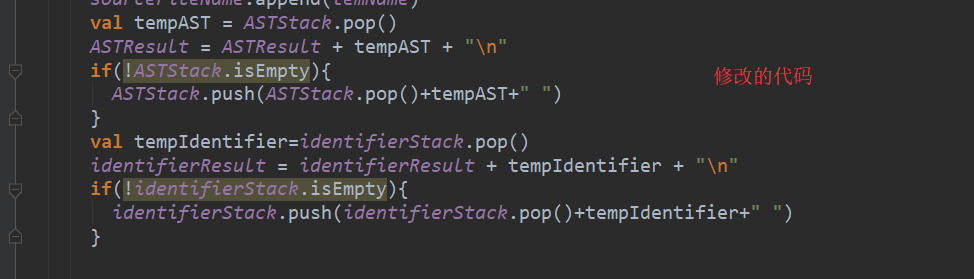
- 父函数提取的数据相似,但是里面的子函数并不相似,所以我决定把子函数嵌入到父函数的数据里面
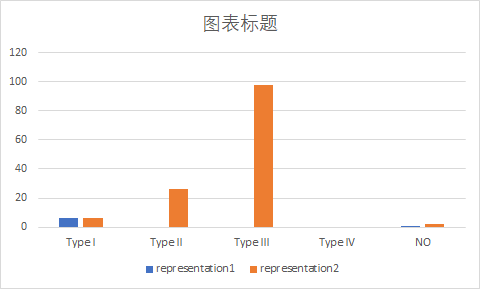
然后跑了一下scala语言的代码,统计了一下结果

最新的项目地址
- 整合工具: http://125.220.157.228/xuyisen/clone_detection_tools
- scala parser: http://125.220.157.228/clone_detection/clone_detector
- 历史数据: https://pan.baidu.com/s/1s__XBJyCm2fXlcEP0ae1WQ
项目的运行时间优化
其中可以进行分批次优化的关键步骤就是在词向量转化为句向量的过程中,目前可以采用的方法就是多个电脑并行运行这一步骤,然后将结果汇总统计距离,也可以启用多进程或者线程。