
AST树提取进展
Published:
今天主要把昨天没有做完的工作进行了扩展,由提取单一文件的叶子节点扩展到提取到整个项目的叶子节点,然后将类级别的数据修改成方法级别的数据
- 实验步骤:
- 按照昨天写的代码,只需要加一个循环遍历文件的函数就可以了
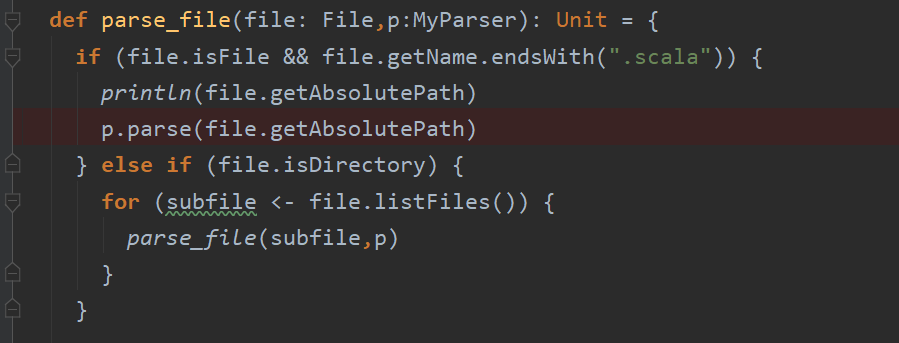 然后第一个问题出现了,scala meta 这个工具还不是很成熟,对于部分文件在parse的时候会抛出异常
然后第一个问题出现了,scala meta 这个工具还不是很成熟,对于部分文件在parse的时候会抛出异常  在网上查了好久,网上也有许多人遇到这个问题,但是scala meta并没有提供解决的办法。经过不懈的努力,最终在评论区找到了解决方法,这个bug主要是
在网上查了好久,网上也有许多人遇到这个问题,但是scala meta并没有提供解决的办法。经过不懈的努力,最终在评论区找到了解决方法,这个bug主要是s"xxxxxxx"后面直接换行引起的(黑人问号),只要在\n后面加一个空格就可以了(黑人问号)。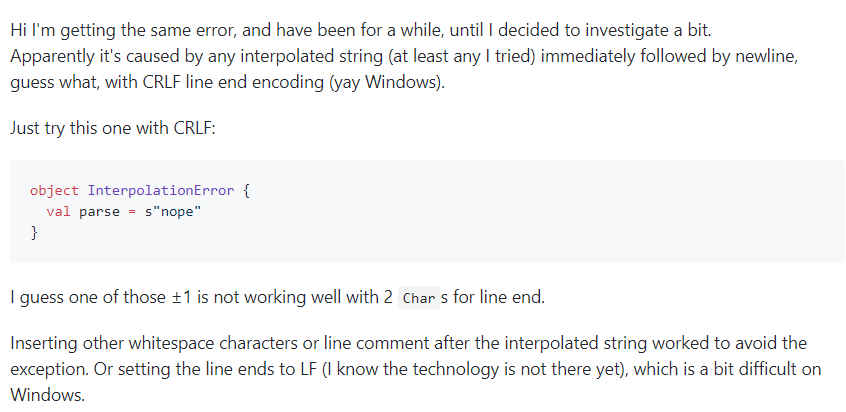 所以我就对我们输入的数据进行了预处理,所有包含字符串
所以我就对我们输入的数据进行了预处理,所有包含字符串s"xxxxx"的行的\n都进行了变换。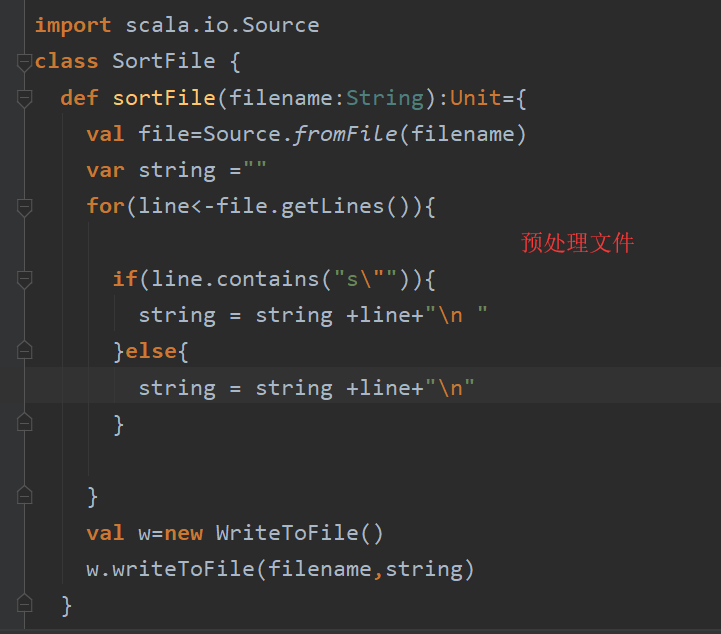
- 第二个问题,嵌套函数的问题,因为我们测试的数据是在方法级别上的进行抽取,所以就会出现嵌套函数的问题,具体的嵌套函数的示例如下图所示:
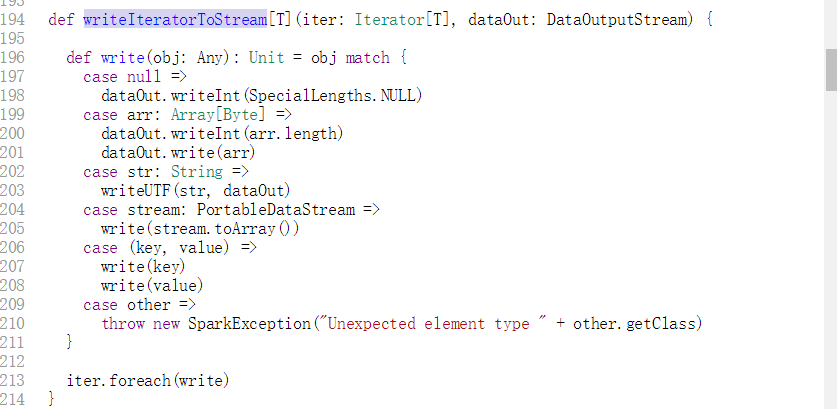 在这里的问题主要是将子函数抽取出来作为一条数据还是将子函数作为一条像if语句那样的句子作为父函数的一部分,经过跟几位老师讨论,我们决定采用第一种方式,原因是第一子函数的粒度小,第二就是在函数的功能上面还是子函数为主,对于第四种类型的代码克隆的判断来说更加有利。所以我利用栈的思想将子函数剥离出来:
在这里的问题主要是将子函数抽取出来作为一条数据还是将子函数作为一条像if语句那样的句子作为父函数的一部分,经过跟几位老师讨论,我们决定采用第一种方式,原因是第一子函数的粒度小,第二就是在函数的功能上面还是子函数为主,对于第四种类型的代码克隆的判断来说更加有利。所以我利用栈的思想将子函数剥离出来: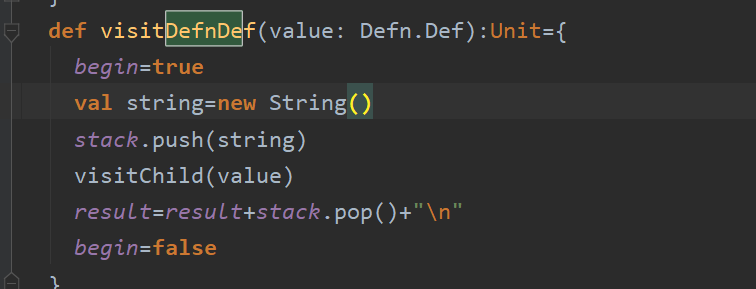
最终的结果是: 其中13是父函数,12是子函数。
其中13是父函数,12是子函数。
- 按照昨天写的代码,只需要加一个循环遍历文件的函数就可以了
- 最终结果:
- 成功提取spark代码里面的27042条样本,明天开始进行测试算法效果,并且再读一遍论文,整理一下文档
 加油!!!! 还要好好学一下英语和线代和算法!!!
加油!!!! 还要好好学一下英语和线代和算法!!!
- 成功提取spark代码里面的27042条样本,明天开始进行测试算法效果,并且再读一遍论文,整理一下文档