机器学习算法学习
Published:

Published:
Published:
这周主要根据上次讨论的内容统计数据和作图,但是在统计数据的过程中发现了不少问题,因此对实验又重新进行了更新,提高数据的准确度。
Published:
原文链接: https://link.springer.com/content/pdf/10.1007%2Fs10664-018-9622-9.pdf
作者:MSebastian Nielebock,Robert Heumüller,Frank Ortmeier 文章来源: Empir Software Eng 2018 简介: 本文针对lambda expression,提出了concurrent applications与lambda expression可能存在一定联系,并通过一系列实验和实验数据的分析验证了自己的观点。
Published:
这周主要将上周讨论的方法实现了,并将十个项目进行了详细的统计,得到了第一版的数据,从数据中我们或许能看到一点东西。
Published:
本周主要继续之前设计的实验,本打算在一个星期内做完所有实验,结果发现里面有很多问题。
Published:
本周由于雅思笔试,口试延误了很长时间,所以实验做的比较晚。这周主要完成了对scala的一个项目项目的详细统计,统计结果包括高阶函数声明数,高阶函数调用数,以及这两者有什么关系;scala文档对高阶函数的定义;统计泛化功能高阶函数;最后自己总结了一点高阶函数的特点。
Published:
这周主要按照上次开会的内容作了两个实验,第一个是统计20个github上star最多的scala项目中高阶函数的使用情况,第二个是借助github api 查看高阶函数所在文件的创建和修改的人时候固定。
Published:
本周的主要任务是对现有版本的代码进行优化,并通过修改程序代码产生GPU版本的代码,经过试验发现,提速的效果尚可,但不是很明显。
Published:
函数式编程又称泛函编程的一种编程泛型,他将计算机运算视为数学上的函数计算,并且避免使用程序状态以及易变对象。函数编程语言最重要的基础是lambda演算。
Published:
这一周主要对项目中代码存在的问题做了一点修改,同时想了一下如何对项目运行时间进行优化
Published:
原文链接:https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16492/16072
作者:Yuding Liang, Kenny Q. Zhu
简介:本文提出了一个新的框架来自动生成源代码块的描述性注释。提出了一个新的递归神经网络-Code-RNN。通过Code-RNN从源码中提取特征并嵌入向量中。当此向量输入到新的递归神经网络Code-GRU时,生成准确率较高的代码注释。
Published:
本博客主要对scala 函数式语言及其二进制代码进行分析,讨论第四种类型代码克隆的检测方法。
Published:
Published:
本博客主要是对上星期统计的数据不正常现象做对比实验,观察最终结果。
Published:
本博客主要对跑出来的clone对进行打标签和统计数据
Published:
本博客对计算机网络的基础知识进行了简单的梳理
Published:
由于临近夏令营,所以将之前的知识整理一下,好面试和笔试。本文是根据《数据结构–使用c++语言描述(第二版)》来进行复习的。
Published:
本文主要介绍根据前几次的实验,编写、整合一个用于检测scala代码克隆的工具,目前只是第一版本。
Published:
原文链接: http://www.cs.wm.edu/~mtufano/publications/C9.pdf
作者:Michele Tufano,Cody Watson,Gabriele Bavota,Massimiliano Di Penta,Martin White,Denys Poshyvanyk
文章来源: MSR 2018
简介: 本文针对代码克隆检测,提出了基于Deep Learning自动学习代码相似性的方法,在混合四个representation的代码克隆检测中取得了较好的结果。
Published:
本文主要介绍利用soot工具提取class文件中的cfg特征,并通过GEM(graph embedding Method)来求流程图之间的相似性。
Published:
按照Michele等人的论文,加下来应该提取的特征是流程图和二进制特征,但是由于流程图提取的过程中出现很多问题,所以今天我先把二进制代码特征提取看了下。
Published:
Published:
a keep-fit studio : 一个健身室 , 没听出来,听到了前面的 Fresham Sports Center,这个说的是另外一个Club所以第一题没听出来。swimming ,听力关键词 and,thenyoga classes:瑜伽a salad bar:一间沙拉吧,关键词at the moment,没听出来assessment:评估、估算 关键词well,等价替换:an assessment with an instruction = instuction's assessmentJanuary February March April May June July August September October November DecemberMonday Tuesday Wednesday Thursday Friday Saturday Sundaythen 等价替换:with its own access = give separate entrancereopen = temporarily closed :暂时关闭fewer seats = reduced in numbertwice as many = doubled in numbernew lifts = replaced 新的电梯那就说明原来的电梯被换掉了two large rooms = increased in sizesoin fact nowbut nowreading已经被排除了,writing主人公已经做完了,根据排除法就可以选出attend a class 等价替换:sit in on a teaching room = attend a class:坐在教室in advance:提前,注意写完整,一个短语nursery:儿童室,育婴室,单词不认识,没听出来annual fee:年费,关键词butask him or her里面的him her 指代前面说的tutor,一般这样的题很那听出来,连读your tutorlaptops printers:注意复数,关键词:and hiremarketing:营销、促销,注意单词拼写,关键词:andindividual:个人,关键词:andmetal leather:金属和皮革:等价转换metal and leather goods = goods made of metal and leatherrestrictions:限制,注意复数,关键词:and,等价替换:fewer = lack ofships:船,这道题在于理解,船的建造加速了世界间的贸易,好多词都被替换掉了,constructed = builded:建造England,这道题的答案出现在所有关键词的前面,很难听对build 关键词:so andpoverty:贫困贫穷,富的人搬走了,只有那个极度贫穷的人还在这个地方,关键词:andunsympathetic landlord:没有同情心的房东,heating problems:取热问题Published:
AST 节点类型提取出来,然后输入到模型中进行了验证Published:
AutoenCODE中 :AutoenCODE is a Deep Learning infrastructure that allows to encode source code fragments into vector representations, which can be used to learn similarities. https://github.com/micheletufano/AutoenCODE 基本上所有的代码这个网站已经提供了,所以只要将代码clone到本地,配置一下环境就可以开始我们的实验。具体的AutoenCODE的原理,我会在以后的博客中详细的解释,本篇博客主要讲如何使用这个框架。AutoenCODE给的教程,第一步是将我们整理的数据转化成词向量,这里他使用的工具是word2vec,这里注意一下,他的这个word2vec需要build但是windows系统不支持这个build,所以我将转化词向量的这部分的工作转移到了centos服务器上进行,最终得到了测试样本的所有的词向量的数据。Recursive Autoencoder(论文中提及是一个斯坦福的情感分析器)中去,最终得到五个结果文件(这里提及一点,训练时间实在是太长了,源代码是使用matlab写的。27000条数据整整跑了一个小时,而且CUP满负荷运行,可能是我的电脑配置低,之后需要优化)。分别是:data.mat contains the input data including the corpus, vocabulary (a 1-by- | V | cell array), and We (the m-by- | V | word embedding matrix where m is the size of the word vectors). So columns of We correspond to word embeddings. |
corpus.dist.matrix.mat contains the distance matrix saved as matlab file. The values in the distance matrix are doubles that represent the Euclidean distance between two sentences. In particular, the cell (i,j) contains the Euclidean distance between the i-th sentence (i.e., i-th line in corpus.src) and the j-th sentence in the corpus.corpus.dist.matrix.csv contains the distance matrix saved as .csv file.corpus.sentence_codes.mat contain the embeddings for each sentence in the corpus. The sentence_codes object contains the representations for sentences, and the pairwise Euclidean distance between these representations are used to measure similarity.detector.mat contains opttheta (the trained clone detector), hparams, and options.Published:
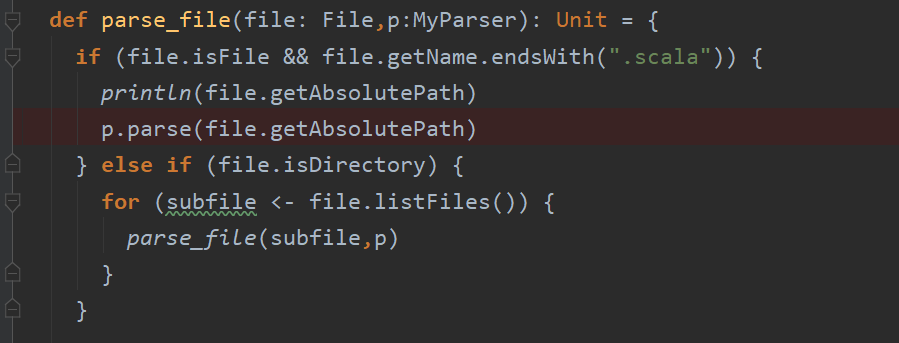 然后第一个问题出现了,scala meta 这个工具还不是很成熟,对于部分文件在parse的时候会抛出异常
然后第一个问题出现了,scala meta 这个工具还不是很成熟,对于部分文件在parse的时候会抛出异常  在网上查了好久,网上也有许多人遇到这个问题,但是scala meta并没有提供解决的办法。经过不懈的努力,最终在评论区找到了解决方法,这个bug主要是
在网上查了好久,网上也有许多人遇到这个问题,但是scala meta并没有提供解决的办法。经过不懈的努力,最终在评论区找到了解决方法,这个bug主要是s"xxxxxxx"后面直接换行引起的(黑人问号),只要在\n后面加一个空格就可以了(黑人问号)。 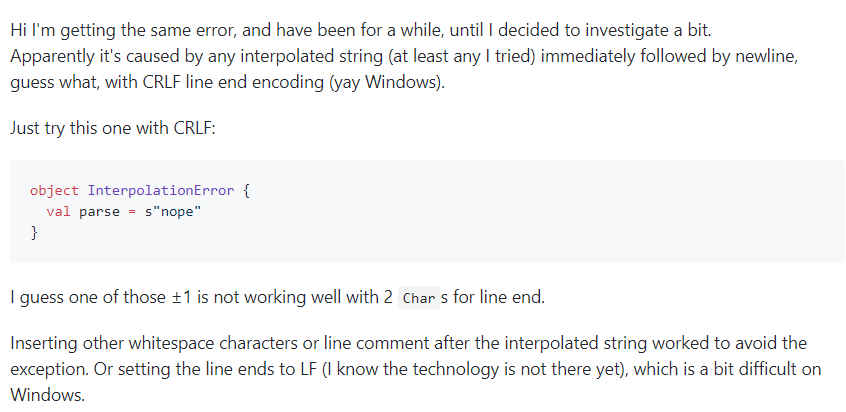 所以我就对我们输入的数据进行了预处理,所有包含字符串
所以我就对我们输入的数据进行了预处理,所有包含字符串s"xxxxx"的行的\n都进行了变换。 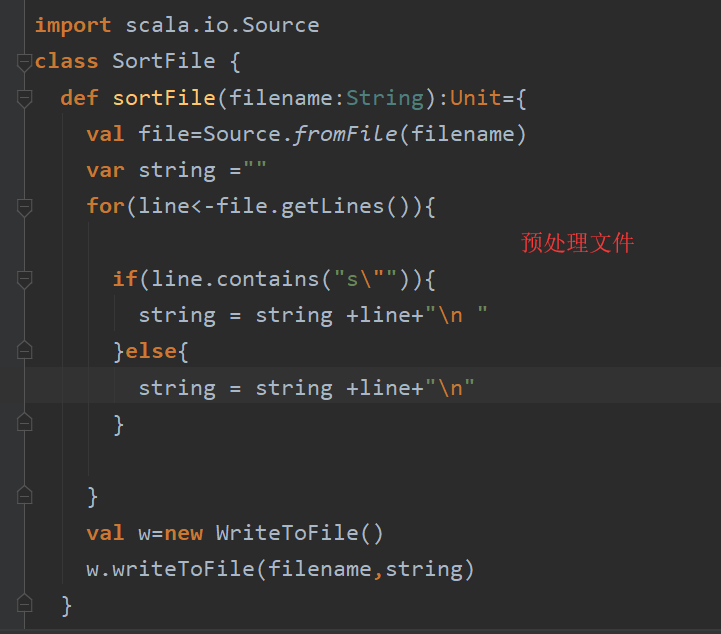
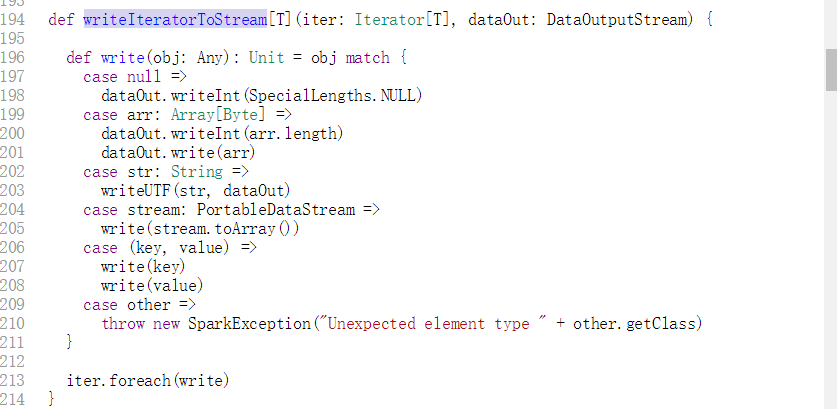 在这里的问题主要是将子函数抽取出来作为一条数据还是将子函数作为一条像if语句那样的句子作为父函数的一部分,经过跟几位老师讨论,我们决定采用第一种方式,原因是第一子函数的粒度小,第二就是在函数的功能上面还是子函数为主,对于第四种类型的代码克隆的判断来说更加有利。所以我利用栈的思想将子函数剥离出来:
在这里的问题主要是将子函数抽取出来作为一条数据还是将子函数作为一条像if语句那样的句子作为父函数的一部分,经过跟几位老师讨论,我们决定采用第一种方式,原因是第一子函数的粒度小,第二就是在函数的功能上面还是子函数为主,对于第四种类型的代码克隆的判断来说更加有利。所以我利用栈的思想将子函数剥离出来: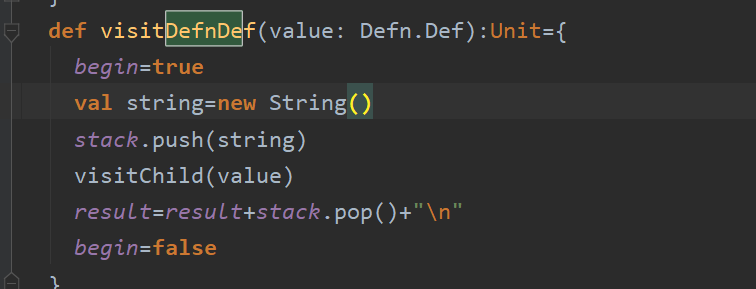
 其中13是父函数,12是子函数。
其中13是父函数,12是子函数。 加油!!!! 还要好好学一下英语和线代和算法!!!
加油!!!! 还要好好学一下英语和线代和算法!!!Published:
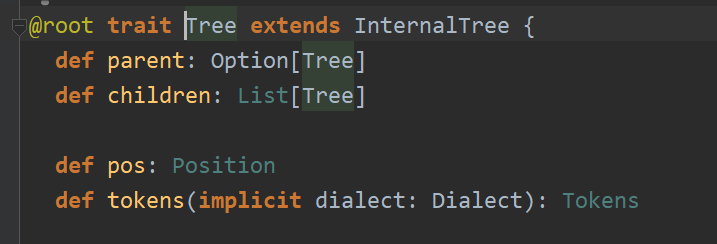 所以可以根据这个类来进行遍历得到我们需要的叶子节点的数据,在这里我采用visitor的方式来进行遍历。主要的遍历的对象有以下几个:
所以可以根据这个类来进行遍历得到我们需要的叶子节点的数据,在这里我采用visitor的方式来进行遍历。主要的遍历的对象有以下几个: 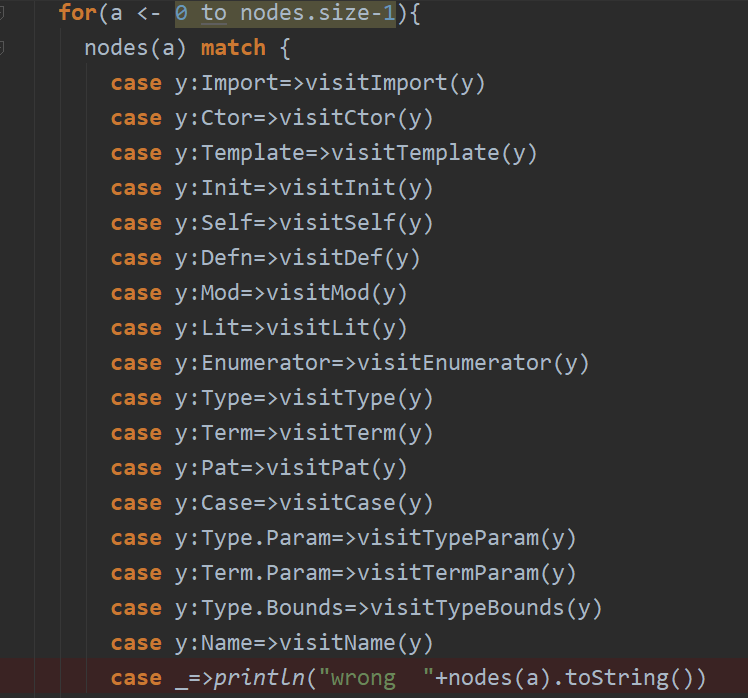 分别代表Scala中的各个语法,这里在做的时候出现了几个问题。一个是Term.param和Type.param 需要“精准的查找”,不能像其他的Term.Name,Term.Annonate那样,可以通过Term来进行查找:
分别代表Scala中的各个语法,这里在做的时候出现了几个问题。一个是Term.param和Type.param 需要“精准的查找”,不能像其他的Term.Name,Term.Annonate那样,可以通过Term来进行查找: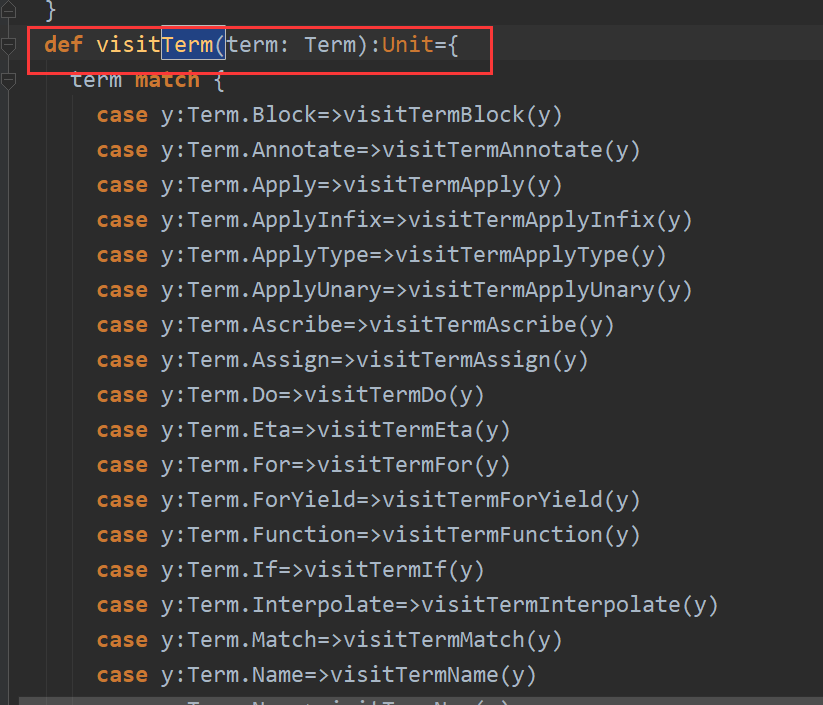 也就是说其他的Term里面的属性可以通过遍历Term然后再进行查找,但是这个Term.param必须在第一次遍历的时候就指出来,难道Term.param不属于Term?很奇怪。以后再查一查。
也就是说其他的Term里面的属性可以通过遍历Term然后再进行查找,但是这个Term.param必须在第一次遍历的时候就指出来,难道Term.param不属于Term?很奇怪。以后再查一查。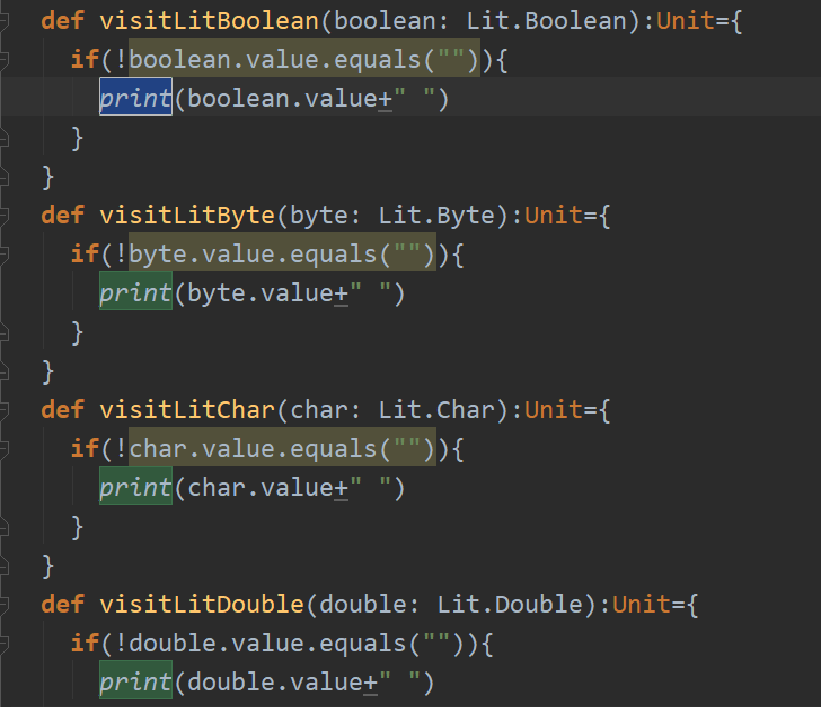 基本数据类型
基本数据类型 Term.Name处
Term.Name处 Type.Name 处 还有一个是Name处
Type.Name 处 还有一个是Name处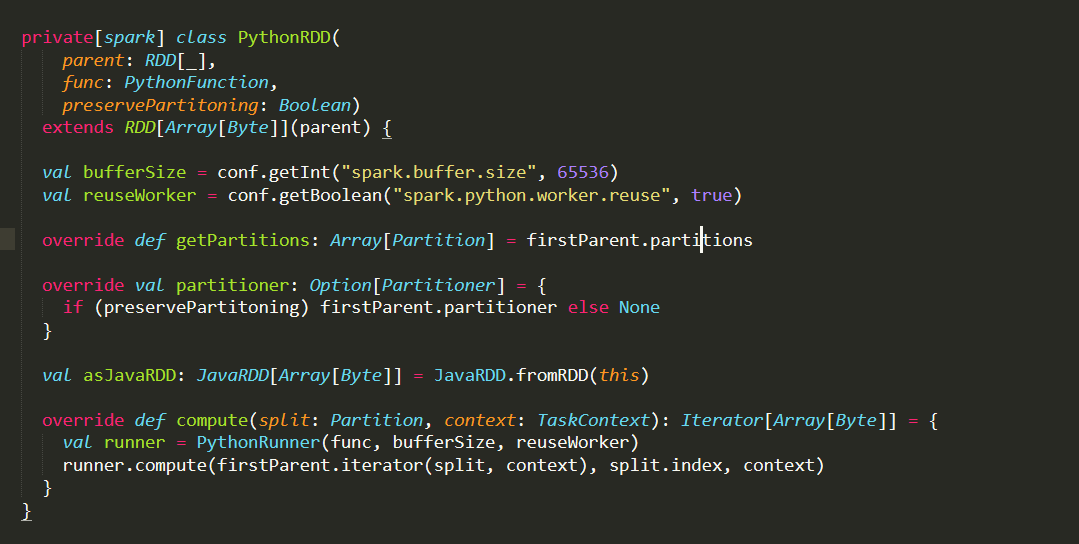 Scala 源代码
Scala 源代码 提取的叶子节点
提取的叶子节点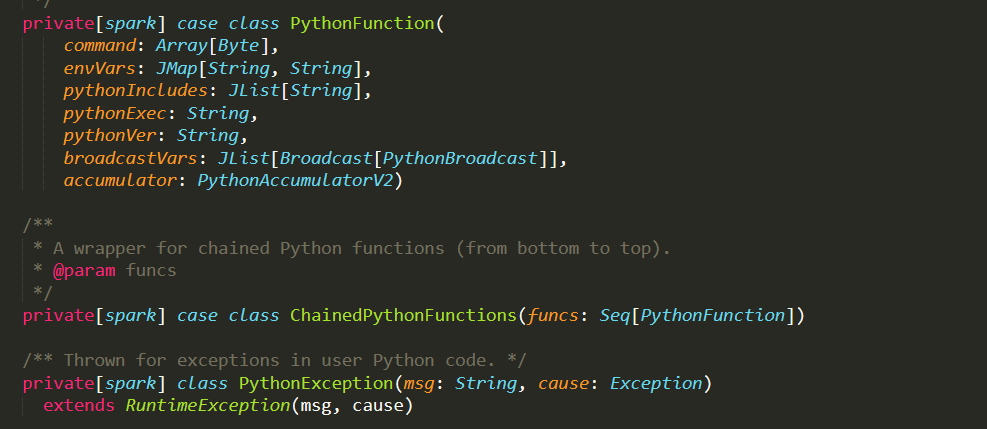 源代码
源代码 提取的叶子节点
提取的叶子节点